I'm now at the point where I can successfully run our entire application test suite, not just the stdlib ones. Here's how much the database grows in each version:
cSuneido: 20 mb
immudb1: 400 mb :-(
immudb2: 19 mb :-)
I'm happy that my decision to back up and try a different approach turned out to be a good one.
It's not too surprising that immudb2 gives slightly better results than cSuneido for running tests, since it will often avoid persisting indexes for temporary tables, whereas cSuneido will always write them.
NOTE: This is still not a realistic workload. I suspect immudb will end up having more database growth than cSuneido. But as long as it's not excessive (as these results would tend to indicate) then it's ok.
Thursday, March 29, 2012
Tuesday, March 27, 2012
Preliminary Immudb Results
I ran a few tests for database growth on the new version of my immudb append-only database storage engine for jSuneido.
First, I tested with persisting indexes every update transaction. This is more or less what it did previously. Then I tested with persisting every so many update transactions.
every 1 = growth 5,882,408
every 10 = growth 1,322,712
every 100 = growth 551,080
every 1000 = growth 354,168
This is the kind of results I was counting on. Deferring persisting the indexes results in much less growth.
Coincidentally, the improvement shown above is about 17 times, not far from the 20 times difference between cSuneido and the first version of immudb. This is just coincidence since I'm running different tests, but it's very nice to see that the improvement may be enough to bring immudb into the same ballpark as cSuneido, which is pretty good considering cSuneido is a mutable database.
Is persisting every 1000 update transactions reasonable? I think so. These tests only take about 5 seconds to run. Remember, the actual data is being written right away, log style, so persisting less often does not increase the risk of losing data. It only increases the amount of work to be done by crash recovery. Making crash recovery re-process 5 seconds (or more) of transactions seems fine. Especially considering that cSuneido rebuilds the entire indexes after a crash, which could take a long time for a big database.
These numbers are from running the stdlib (standard library) tests. This isn't a very typical work load, so the numbers aren't going to be very accurate. But I'm just looking for some very rough feedback at this point. If I'd seen little or no improvement, I'd be seriously depressed right now and considering taking up golf instead :-)
Ideally, I need a good statistical model of a typical work load, or at least representative, since there's probably no such thing as typical. Another project for my "spare" time!
Hmmm... thinking about what the stdlib tests do versus what a typical workload might be, I realized that one atypical thing the stdlib tests do is to create, use, and then drop temporary database tables. But in that case, if you defer persisting till after the table is dropped, then you never need to save the indexes for that table at all. (Although the data will still be written immediately, log style.)
It turned out I wasn't handling this, which actually was good because it would have seriously skewed the above results. It was easy enough to fix.
Rerunning the tests, I got the results I expected - much the same growth when persisting every transaction, less growth than before as the persist interval increased. Persisting every 1000 transactions resulted in a growth of only 62,424 - roughly 5 times better.
This is nice, but not really relevant to production, since a typical workload does not include creating and dropping a lot of temporary tables. It will be nice for development because running the tests won't cause the database to grow so much. (At least until I implement background compaction.)
Persisting every so many update transactions is not necessarily the best approach, I'm using it because it's the easiest. Alternately, you could persist every so many seconds or minutes, or try to persist during "idle" times. Currently, I'm persisting synchronously i.e. while holding the same lock that commits use. So update transactions can't commit till the persist finishes. (But read-only transactions are not affected, and even update transactions can read and write, they just have to wait to commit.) Depending on how much index information has to be persisted, this could introduce delays in server response. To alleviate this, you could persist in a background thread. Because of the immutability, this should be relatively straightforward. The exception is updating the in-memory index information to show it has been saved - this would require some synchronization.
Another issue I haven't dealt with is that I may need to "flush" some of the index information out of memory. Once it's been stored, a btree node in memory consists mainly of a ByteBuffer that points to part of the memory mapped index file. Since the memory mapped space is "virtual", it will get evicted if the OS runs short on memory. But for a really big database, even the small objects referencing the virtual memory may add up to too much memory usage.
It would be easy enough for the persist process to discard the btree nodes once they have been saved. But that would have an effect on performance since they would have to be recreated on-demand. You'd want to evict selectively, presumably on some kind of LRU or NFU basis, which would require tracking some kind of usage data. Presumably, you'd also only want to do this when necessary, i.e. when memory is getting full. Hmmm... perhaps one approach would be to use WeakReference's and let Java worry about when and what to evict. Anyway, that's a challenge for another day.
And now back to testing :-)
First, I tested with persisting indexes every update transaction. This is more or less what it did previously. Then I tested with persisting every so many update transactions.
every 1 = growth 5,882,408
every 10 = growth 1,322,712
every 100 = growth 551,080
every 1000 = growth 354,168
This is the kind of results I was counting on. Deferring persisting the indexes results in much less growth.
Coincidentally, the improvement shown above is about 17 times, not far from the 20 times difference between cSuneido and the first version of immudb. This is just coincidence since I'm running different tests, but it's very nice to see that the improvement may be enough to bring immudb into the same ballpark as cSuneido, which is pretty good considering cSuneido is a mutable database.
Is persisting every 1000 update transactions reasonable? I think so. These tests only take about 5 seconds to run. Remember, the actual data is being written right away, log style, so persisting less often does not increase the risk of losing data. It only increases the amount of work to be done by crash recovery. Making crash recovery re-process 5 seconds (or more) of transactions seems fine. Especially considering that cSuneido rebuilds the entire indexes after a crash, which could take a long time for a big database.
These numbers are from running the stdlib (standard library) tests. This isn't a very typical work load, so the numbers aren't going to be very accurate. But I'm just looking for some very rough feedback at this point. If I'd seen little or no improvement, I'd be seriously depressed right now and considering taking up golf instead :-)
Ideally, I need a good statistical model of a typical work load, or at least representative, since there's probably no such thing as typical. Another project for my "spare" time!
Hmmm... thinking about what the stdlib tests do versus what a typical workload might be, I realized that one atypical thing the stdlib tests do is to create, use, and then drop temporary database tables. But in that case, if you defer persisting till after the table is dropped, then you never need to save the indexes for that table at all. (Although the data will still be written immediately, log style.)
It turned out I wasn't handling this, which actually was good because it would have seriously skewed the above results. It was easy enough to fix.
Rerunning the tests, I got the results I expected - much the same growth when persisting every transaction, less growth than before as the persist interval increased. Persisting every 1000 transactions resulted in a growth of only 62,424 - roughly 5 times better.
This is nice, but not really relevant to production, since a typical workload does not include creating and dropping a lot of temporary tables. It will be nice for development because running the tests won't cause the database to grow so much. (At least until I implement background compaction.)
Persisting every so many update transactions is not necessarily the best approach, I'm using it because it's the easiest. Alternately, you could persist every so many seconds or minutes, or try to persist during "idle" times. Currently, I'm persisting synchronously i.e. while holding the same lock that commits use. So update transactions can't commit till the persist finishes. (But read-only transactions are not affected, and even update transactions can read and write, they just have to wait to commit.) Depending on how much index information has to be persisted, this could introduce delays in server response. To alleviate this, you could persist in a background thread. Because of the immutability, this should be relatively straightforward. The exception is updating the in-memory index information to show it has been saved - this would require some synchronization.
Another issue I haven't dealt with is that I may need to "flush" some of the index information out of memory. Once it's been stored, a btree node in memory consists mainly of a ByteBuffer that points to part of the memory mapped index file. Since the memory mapped space is "virtual", it will get evicted if the OS runs short on memory. But for a really big database, even the small objects referencing the virtual memory may add up to too much memory usage.
It would be easy enough for the persist process to discard the btree nodes once they have been saved. But that would have an effect on performance since they would have to be recreated on-demand. You'd want to evict selectively, presumably on some kind of LRU or NFU basis, which would require tracking some kind of usage data. Presumably, you'd also only want to do this when necessary, i.e. when memory is getting full. Hmmm... perhaps one approach would be to use WeakReference's and let Java worry about when and what to evict. Anyway, that's a challenge for another day.
And now back to testing :-)
Sunday, March 25, 2012
jSuneido immudb milestone
The improved version of the jSuneido append-only storage engine (immudb) now passes all the standard library tests.
Which is great, except it just means I'm right back where I was two months ago with my previous jSuneido immudb milestone. As usual, it feels like I only started on this a couple of weeks ago.
Except that hopefully I've fixed the database growth and transaction conflict issues.
I haven't implemented the idea of passing the table select predicate down to the transaction so it can use it for read validation. But even without this, the conflict detection should be at least as fine grained as cSuneido (and much better than previous versions of jSuneido).
I'm almost to the point where my strangler fig approach has taken over the old immudb code and I should go back and clean it all up so I have a single version. I can't see needing the old immudb version again (and it'll be in version control if I do).
The last problem I ran into was a tricky one. In order to defer btree updates till commit, I use transaction local btrees. Which means to access an index you have to look at both the local and the global btrees. To do this I use an iterator that merges two other iterators. Iterating through two sorted sequences in parallel is a standard easy problem. But Suneido allows you to bidirectionally step forwards or backwards in any order with the same iterator. And it turns out that this makes iterating in parallel a lot tougher. The trick is when you change directions. The final code is not that large (look at next and prev in MergeIndexIter) but I went through about six different versions before I finally got one that appears to work. Of course, most of my previous versions also appeared to work, until I added more test cases.
A big part of finally figuring this out was coming up with the right visualization for it. Here's what I ended up with:

Notice it's paper and pencil. (It should have been on graph paper but I so seldom do stuff on paper anymore that I didn't have any handy.) I would have preferred to do it digital, but I couldn't think of an easy way to do it. I could have done it in a drawing program or even a spreadsheet or word processor, but it would have been a hassle. Drawing programs make it possible to do just about anything, but they'd don't tend to make it easy and natural (at least, if you only use them occasionally like me). Maybe there's a market niche for someone to go after. Or maybe there already is a good program for doing this - anyone know one?
Given the extra complexity, I started to question whether Suneido needed to allow you to switch directions with an iterator. I can only think of a couple of places where we use this. But I'll leave that question for another day.
And now back to testing. I imagine I've still got a few bugs lurking in there. I also need to do some testing and see whether I've actually solved the database growth problem. It may be harder to know whether the transaction issue is solved until we actually get it in production.
Which is great, except it just means I'm right back where I was two months ago with my previous jSuneido immudb milestone. As usual, it feels like I only started on this a couple of weeks ago.
Except that hopefully I've fixed the database growth and transaction conflict issues.
I haven't implemented the idea of passing the table select predicate down to the transaction so it can use it for read validation. But even without this, the conflict detection should be at least as fine grained as cSuneido (and much better than previous versions of jSuneido).
I'm almost to the point where my strangler fig approach has taken over the old immudb code and I should go back and clean it all up so I have a single version. I can't see needing the old immudb version again (and it'll be in version control if I do).
The last problem I ran into was a tricky one. In order to defer btree updates till commit, I use transaction local btrees. Which means to access an index you have to look at both the local and the global btrees. To do this I use an iterator that merges two other iterators. Iterating through two sorted sequences in parallel is a standard easy problem. But Suneido allows you to bidirectionally step forwards or backwards in any order with the same iterator. And it turns out that this makes iterating in parallel a lot tougher. The trick is when you change directions. The final code is not that large (look at next and prev in MergeIndexIter) but I went through about six different versions before I finally got one that appears to work. Of course, most of my previous versions also appeared to work, until I added more test cases.
A big part of finally figuring this out was coming up with the right visualization for it. Here's what I ended up with:
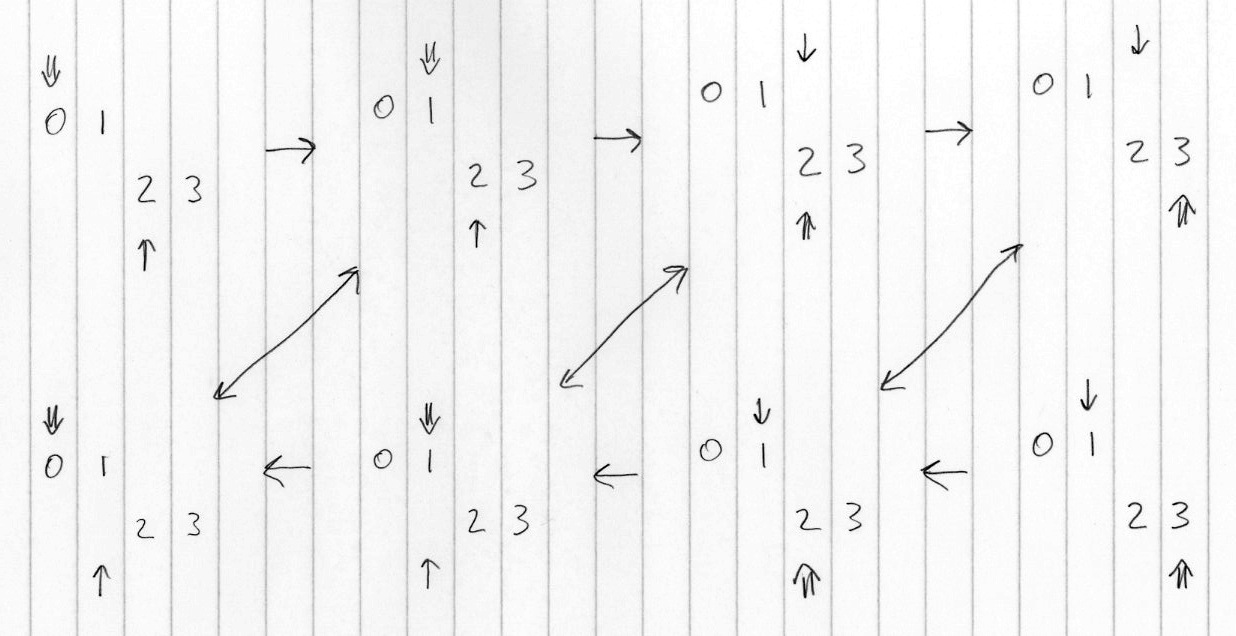
Notice it's paper and pencil. (It should have been on graph paper but I so seldom do stuff on paper anymore that I didn't have any handy.) I would have preferred to do it digital, but I couldn't think of an easy way to do it. I could have done it in a drawing program or even a spreadsheet or word processor, but it would have been a hassle. Drawing programs make it possible to do just about anything, but they'd don't tend to make it easy and natural (at least, if you only use them occasionally like me). Maybe there's a market niche for someone to go after. Or maybe there already is a good program for doing this - anyone know one?
Given the extra complexity, I started to question whether Suneido needed to allow you to switch directions with an iterator. I can only think of a couple of places where we use this. But I'll leave that question for another day.
And now back to testing. I imagine I've still got a few bugs lurking in there. I also need to do some testing and see whether I've actually solved the database growth problem. It may be harder to know whether the transaction issue is solved until we actually get it in production.
Friday, March 23, 2012
I'm a little slow sometimes
A roundabout detour of bit twiddling optimizations that turn out to be ultimately unnecessary.
Originally, Suneido used 32 bit database file offsets. Remember when disks (let alone files) were limited to 4 gb? When we needed to support databases larger than 4 gb, I didn't want to switch to 64 bit offsets because of the extra space required to store them, so I "compressed" larger offsets into 32 bits. (a bit like the Java -XX:+UseCompressedOops option)
The approach I used was to align and shift. If you align the data in the file on, for example, 8 byte boundaries, then the lower 3 bits of an offset will always be zero. So you can shift a 35 bit offset to the right 3 bits so it fits into 32 bits. (Who says bit twiddling is dead?) This allows a maximum file size of 32 gb instead of 4 gb. (Actually, for obscure historical reasons, even though the alignment is 8 bytes, the shift is only 2 bits, so the maximum size is 16 gb.)
The tradeoff is some wasted space. Each block of data will waste an average of 4 bytes.
The problem is, it's starting to look like we need to allow even larger databases. I could just increase the align/shift to 16 bytes/4 bits to allow 64 gb. But that would increase the average waste to 8 bytes, even though most databases aren't that big.
Ideally, you'd want small databases to use a small align/shift, and larger databases to use a larger align/shift. I could make the align/shift a command line option, but you'd have to rebuild the database to change it. And I'm not a big fan of cryptic options that most people won't understand.
My next thought was to use a variable align/shift. There are different ways you could do this, but a simple one would be to reserve two bits to specify the align/shift. This would leave 30 bits (1 gb range) for the unshifted offset. For example:
00 = 4 byte alignment = 0 to 4 gb
01 = 8 byte alignment = 4 to 12 gb
10 = 16 byte alignment = 12 to 28 gb
11 = 32 byte alignment = 28 to 50 gb
For databases up to 4 gb, this would use a smaller alignment than currently and therefore less wasted space, while still allow a much higher maximum size than now. Only large databases would pay the cost of higher wastage due to larger alignment.
This scheme would be slightly more complex to decode, but not too bad.
At first I was excited about this approach, but it doesn't scale. You can increase alignment to allow bigger files, but then you waste more and more space. At some point, you'd be further ahead to drop the alignment and just store 64 bit offsets. Except you don't want the overhead of large offsets on small databases.
So why not just use a variable length encoding like Google Protocol Buffer varint?
A variable length encoding would not be the simplest thing to manipulate in the code, but we don't have large numbers of offsets in memory, so you could use 64 bit unencoded offsets in memory, and just use the variable length encoding on disk.
At this point I whack myself on the forehead. D'oh! Sometimes I am such an idiot! (A lot of my "aha!" moments are spoiled by thinking that if I was just a little bit smarter and had thought of it a little sooner, I could have saved myself a lot of work.)
Suneido already uses a variable length encoding when storing file offsets!
The offsets are stored in the btree key records. They are getting encoded the same way other numeric values are packed into records, which is a already a variable length encoding.
So all the messing around with align/shift is mostly wasted effort. It does reduce the magnitude of the offsets, which does mean they are encoded slightly smaller, but this is minor.
I'd be further ahead to drop the align/shift altogether, use 64 bit offsets in memory, and let the variable length encoding handle making small offsets small. This would eliminate the whole maximum database file size issue!
If I want to save space, I could use a different variable length encoding for offsets. The current encoding is designed for Suneido's decimal floating point numbers and is not ideal for simple integers.
I can't use the Protocol Buffer varint encoding because I need encoded integers to sort in the same order as the original values. varint's don't because they are stored least significant first. One simple approach would be to reserve the first two bits to specify the length of the value, for example:
00 = 4 bytes
01 = 5 bytes
10 = 6 bytes
11 = 7 bytes
This would give a maximum of 54 bits (7 * 8 - 2) or about 16,000 terabytes. By the time anyone is trying to make a Suneido database bigger than that, it should be someone else's problem :-)
Of course, I'm itching to implement this, but I'm in the middle of debugging my immudb improvements so it'll have to wait.
Originally, Suneido used 32 bit database file offsets. Remember when disks (let alone files) were limited to 4 gb? When we needed to support databases larger than 4 gb, I didn't want to switch to 64 bit offsets because of the extra space required to store them, so I "compressed" larger offsets into 32 bits. (a bit like the Java -XX:+UseCompressedOops option)
The approach I used was to align and shift. If you align the data in the file on, for example, 8 byte boundaries, then the lower 3 bits of an offset will always be zero. So you can shift a 35 bit offset to the right 3 bits so it fits into 32 bits. (Who says bit twiddling is dead?) This allows a maximum file size of 32 gb instead of 4 gb. (Actually, for obscure historical reasons, even though the alignment is 8 bytes, the shift is only 2 bits, so the maximum size is 16 gb.)
The tradeoff is some wasted space. Each block of data will waste an average of 4 bytes.
The problem is, it's starting to look like we need to allow even larger databases. I could just increase the align/shift to 16 bytes/4 bits to allow 64 gb. But that would increase the average waste to 8 bytes, even though most databases aren't that big.
Ideally, you'd want small databases to use a small align/shift, and larger databases to use a larger align/shift. I could make the align/shift a command line option, but you'd have to rebuild the database to change it. And I'm not a big fan of cryptic options that most people won't understand.
My next thought was to use a variable align/shift. There are different ways you could do this, but a simple one would be to reserve two bits to specify the align/shift. This would leave 30 bits (1 gb range) for the unshifted offset. For example:
00 = 4 byte alignment = 0 to 4 gb
01 = 8 byte alignment = 4 to 12 gb
10 = 16 byte alignment = 12 to 28 gb
11 = 32 byte alignment = 28 to 50 gb
For databases up to 4 gb, this would use a smaller alignment than currently and therefore less wasted space, while still allow a much higher maximum size than now. Only large databases would pay the cost of higher wastage due to larger alignment.
This scheme would be slightly more complex to decode, but not too bad.
At first I was excited about this approach, but it doesn't scale. You can increase alignment to allow bigger files, but then you waste more and more space. At some point, you'd be further ahead to drop the alignment and just store 64 bit offsets. Except you don't want the overhead of large offsets on small databases.
So why not just use a variable length encoding like Google Protocol Buffer varint?
A variable length encoding would not be the simplest thing to manipulate in the code, but we don't have large numbers of offsets in memory, so you could use 64 bit unencoded offsets in memory, and just use the variable length encoding on disk.
At this point I whack myself on the forehead. D'oh! Sometimes I am such an idiot! (A lot of my "aha!" moments are spoiled by thinking that if I was just a little bit smarter and had thought of it a little sooner, I could have saved myself a lot of work.)
Suneido already uses a variable length encoding when storing file offsets!
The offsets are stored in the btree key records. They are getting encoded the same way other numeric values are packed into records, which is a already a variable length encoding.
So all the messing around with align/shift is mostly wasted effort. It does reduce the magnitude of the offsets, which does mean they are encoded slightly smaller, but this is minor.
I'd be further ahead to drop the align/shift altogether, use 64 bit offsets in memory, and let the variable length encoding handle making small offsets small. This would eliminate the whole maximum database file size issue!
If I want to save space, I could use a different variable length encoding for offsets. The current encoding is designed for Suneido's decimal floating point numbers and is not ideal for simple integers.
I can't use the Protocol Buffer varint encoding because I need encoded integers to sort in the same order as the original values. varint's don't because they are stored least significant first. One simple approach would be to reserve the first two bits to specify the length of the value, for example:
00 = 4 bytes
01 = 5 bytes
10 = 6 bytes
11 = 7 bytes
This would give a maximum of 54 bits (7 * 8 - 2) or about 16,000 terabytes. By the time anyone is trying to make a Suneido database bigger than that, it should be someone else's problem :-)
Of course, I'm itching to implement this, but I'm in the middle of debugging my immudb improvements so it'll have to wait.
Labels:
suneido

Monday, March 05, 2012
Piracy?
I've been a fan of Pragmatic Programmers and their books for a long time. I buy their books directly, both to maximize their revenue, and to get eBooks without DRM.
Recently I noticed this at the bottom of one of my order emails. (I'm not sure how long they've been including it.)
If I bought a paper copy of the book, and put it on the bookshelf in our company coffee room, I don't think I'd be breaking any laws. But I'm not supposed to do the same thing with a digital copy.
Potentially, multiple people could simultaneously read the digital copy. But I have trouble getting anyone to read any books. The chances of multiple people reading the same book at the same time is slim to nil.
Note: If my staff needs regular access to a book, I have no problem with buying extra copies.
I always thought Prag Prog were more "enlightened" than this. But obviously someone there couldn't resist the urge to "wag their finger" at us.
In some ways, Amazon, despite their DRM, is more flexible. I could buy Kindle books on a company account, and set up multiple Kindle readers (either devices or software) associated with that account. I don't know if Amazon would regard that as entirely legitimate, but they allow it. (Albeit, intended for "families".)
Publishers want to have their cake and eat it too - they want the benefits of digital - no printing, no inventory, no shipping, and at the same time, they want to take away all the traditional rights we had with paper books to share and lend. Some eBooks are now more expensive than the hardcover - what's the story with that? Who are the pirates now?
Recently I noticed this at the bottom of one of my order emails. (I'm not sure how long they've been including it.)
Please don't put these eBooks on the 'net or on file-sharing networks. Sometimes folks do this accidentally by downloading into a shared directory.I don't have any problem with the "don't post these eBooks on the 'net" part. But I really question the file-sharing part - not the legality of it, since I'm no expert on that, but the "morality" of it. Even the 'net part needs to be more specific - I put my books on the "net" - into Dropbox so I can access them from various devices and locations, but they're not public. Of course, maybe that's not "legal" either.
If I bought a paper copy of the book, and put it on the bookshelf in our company coffee room, I don't think I'd be breaking any laws. But I'm not supposed to do the same thing with a digital copy.
Potentially, multiple people could simultaneously read the digital copy. But I have trouble getting anyone to read any books. The chances of multiple people reading the same book at the same time is slim to nil.
Note: If my staff needs regular access to a book, I have no problem with buying extra copies.
I always thought Prag Prog were more "enlightened" than this. But obviously someone there couldn't resist the urge to "wag their finger" at us.
In some ways, Amazon, despite their DRM, is more flexible. I could buy Kindle books on a company account, and set up multiple Kindle readers (either devices or software) associated with that account. I don't know if Amazon would regard that as entirely legitimate, but they allow it. (Albeit, intended for "families".)
Publishers want to have their cake and eat it too - they want the benefits of digital - no printing, no inventory, no shipping, and at the same time, they want to take away all the traditional rights we had with paper books to share and lend. Some eBooks are now more expensive than the hardcover - what's the story with that? Who are the pirates now?
Sunday, March 04, 2012
jSuneido Immudb Progress
I've made good progress on the changes to the append-only database storage engine for jSuneido. The new version now passes all the built-in tests, although I have a few things left to do to improve performance.
I'm pretty happy with how it went. No big surprises and the code turned out quite simple for the most part. It's nice that there's less shared mutable state and therefore less potential locking issues.
Previously, updating the shared state and persisting to disk were a combined process. It was a little tricky teasing this apart so they were independent. For example, the semi-immutable data structures were flipping to immutable when they were stored. Now they have to be flipped to immutable before they go into the shared state, separately from being stored.
Of course, the reason I did all these changes was to try to address some "production scale" issues, and I still haven't got to the point where I can really tell if I've solved them or not. So far, the signs are good.
As usual, the code is in Mercurial on SourceForge
Related: Immudb Progress
I'm pretty happy with how it went. No big surprises and the code turned out quite simple for the most part. It's nice that there's less shared mutable state and therefore less potential locking issues.
Previously, updating the shared state and persisting to disk were a combined process. It was a little tricky teasing this apart so they were independent. For example, the semi-immutable data structures were flipping to immutable when they were stored. Now they have to be flipped to immutable before they go into the shared state, separately from being stored.
Of course, the reason I did all these changes was to try to address some "production scale" issues, and I still haven't got to the point where I can really tell if I've solved them or not. So far, the signs are good.
As usual, the code is in Mercurial on SourceForge
Related: Immudb Progress
Subscribe to:
Comments (Atom)