I use Shift+Command+4 all the time to take screenshots on my Mac.
What I found out recently is that if you press the space bar after Shift+Command+4 then you can capture an entire window or pull down menu, without having to try to manually select its area without cutting off any pixels or including any extra.
Strangely, this doesn't seem to be mentioned in the Mac OS X Leopard Pocket Guide.
I use Techsmith Snagit on Windows and it has a similar option, but I like the Mac keyboard shortcut since it's always available without having to start another program. (I could leave Snagit running, but I prefer to not to have too much stuff running all the time.)
Wednesday, December 31, 2008
Double Speed
We have accumulated quite a large suite of tests for our Suneido applications. It takes about 100 seconds to run them on my work PC.
I happened to run the tests on my iMac (on Vista under Parallels under OS X) and was surprised to see they only took about 50 seconds - twice as fast! My iMac is newer, but I didn't realize it was such a big difference.
One of my rules of thumb over the years has been not to buy a new computer until I could get one twice as fast (for a reasonably priced mainstream machine). No point going through a painful upgrade for a barely noticeable 15 or 20% speed increase.
I usually like to go for the high end of the "normal" range. Buying the low end reduces the lifetime of the machine - it's out of date before you get it. And I'm not going to try to build the "ultimate" machine. You pay too big a premium and have too many problems because you're breaking new ground. And by the time you get it, it's not even ultimate any more.
Doubling the speed has gotten tougher over the years. CPU speeds have leveled out and overall speed is often limited by memory and disk since they haven't improved as much as CPU speeds.
The trend now is towards multi-core, which is great. But when you're still running single-threaded software (like Suneido, unfortunately) then multiple cores don't help much. And the early multi-core cpu's tended to have slower clock speeds and could actually perform worse with single-threaded software.
It's also gotten tougher to judge speed. In the past you could judge by the clock rate - 400 mhz was roughly twice as fast as 200 mhz. (I'm dating myself) But now there are a lot more factors involved - like caches and pipelines and bus speeds. And power consumption has also become more important.
Anyway, my rule of thumb has now triggered and it's time to look for a new machine. I decided I'd look for something small, quiet, and energy efficient yet still reasonably fast (i.e. as fast as my iMac). I looked at the Dell Studio Hybrid and the Acer Veriton L460-ED8400. The Dell is smaller and lower power but more expensive and not as fast - it uses a mobile cpu. The Acer is not as sexy looking but it's faster and cheaper. Both have slot loading DVD drives. For a media computer the Dell has a memory card reader, HDMI output, and you can get it with a Blu-ray drive. The Acer has gigabit ethernet and wireless built in.
Neither machine came with a big enough hard drive. These days I figure 500gb is decent. The Acer only had a 160 gb drive but at least it was 7200 rpm. The Dell offered 250 or 320 gb drives but only 5400 rpm. It seems a little strange considering how cheap drives are.
Ironically, I now find I need more disk space at home (for photos and music) than I do at work. Source code and programs are small. And my email and documents mostly live in the cloud.
I ended up going with the Acer plus upgrading the memory to 4 gb and the drive to 500 gb for about $1000. I paid a bit of a premium to order from a company I'd dealt with before. You can get cheaper machines these days, but it's still a lot cheaper than my iMac.
There are probably a bunch of other alternatives I should have looked at. But I don't have the inclination to spend my time that way. And the paradox of choice tells us that more alternative don't make us happier, in fact often the opposite.
I've also been wanting to run Vista. I know, the rest of the world is trying to downgrade to XP, but I've been running Vista on my Mac (under Parallels) and I don't have a problem with it. It's got some good features. I'm not a huge Windows fan to start with. I was thinking about trying Vista 64 but these machines didn't come with it and I hear there are still driver problems. So to keep things simple I'll stick to Vista 32.
One challenge will be to swap in the bigger hard drive. I assume Windows will come preinstalled on the hard drive in the computer and I won't get an install disk. Normally you'd plug the second hard drive in and copy everything over. But I suspect these small computers don't have room for a second drive. I should be able to plug both drives into another bigger machine that can take multiple drives and do the copy there.
It's always exciting (for a geek) to get a new machine. Of course, the part I'm trying not to think about is getting the new machine configured the way I want it and all my files moved over and software re-installed. Oh well, it's always a good opportunity to clean up and drop a lot of the junk you accumulate over time.
I happened to run the tests on my iMac (on Vista under Parallels under OS X) and was surprised to see they only took about 50 seconds - twice as fast! My iMac is newer, but I didn't realize it was such a big difference.
One of my rules of thumb over the years has been not to buy a new computer until I could get one twice as fast (for a reasonably priced mainstream machine). No point going through a painful upgrade for a barely noticeable 15 or 20% speed increase.
I usually like to go for the high end of the "normal" range. Buying the low end reduces the lifetime of the machine - it's out of date before you get it. And I'm not going to try to build the "ultimate" machine. You pay too big a premium and have too many problems because you're breaking new ground. And by the time you get it, it's not even ultimate any more.
Doubling the speed has gotten tougher over the years. CPU speeds have leveled out and overall speed is often limited by memory and disk since they haven't improved as much as CPU speeds.
The trend now is towards multi-core, which is great. But when you're still running single-threaded software (like Suneido, unfortunately) then multiple cores don't help much. And the early multi-core cpu's tended to have slower clock speeds and could actually perform worse with single-threaded software.
It's also gotten tougher to judge speed. In the past you could judge by the clock rate - 400 mhz was roughly twice as fast as 200 mhz. (I'm dating myself) But now there are a lot more factors involved - like caches and pipelines and bus speeds. And power consumption has also become more important.
Anyway, my rule of thumb has now triggered and it's time to look for a new machine. I decided I'd look for something small, quiet, and energy efficient yet still reasonably fast (i.e. as fast as my iMac). I looked at the Dell Studio Hybrid and the Acer Veriton L460-ED8400. The Dell is smaller and lower power but more expensive and not as fast - it uses a mobile cpu. The Acer is not as sexy looking but it's faster and cheaper. Both have slot loading DVD drives. For a media computer the Dell has a memory card reader, HDMI output, and you can get it with a Blu-ray drive. The Acer has gigabit ethernet and wireless built in.
Neither machine came with a big enough hard drive. These days I figure 500gb is decent. The Acer only had a 160 gb drive but at least it was 7200 rpm. The Dell offered 250 or 320 gb drives but only 5400 rpm. It seems a little strange considering how cheap drives are.
Ironically, I now find I need more disk space at home (for photos and music) than I do at work. Source code and programs are small. And my email and documents mostly live in the cloud.
I ended up going with the Acer plus upgrading the memory to 4 gb and the drive to 500 gb for about $1000. I paid a bit of a premium to order from a company I'd dealt with before. You can get cheaper machines these days, but it's still a lot cheaper than my iMac.
There are probably a bunch of other alternatives I should have looked at. But I don't have the inclination to spend my time that way. And the paradox of choice tells us that more alternative don't make us happier, in fact often the opposite.
I've also been wanting to run Vista. I know, the rest of the world is trying to downgrade to XP, but I've been running Vista on my Mac (under Parallels) and I don't have a problem with it. It's got some good features. I'm not a huge Windows fan to start with. I was thinking about trying Vista 64 but these machines didn't come with it and I hear there are still driver problems. So to keep things simple I'll stick to Vista 32.
One challenge will be to swap in the bigger hard drive. I assume Windows will come preinstalled on the hard drive in the computer and I won't get an install disk. Normally you'd plug the second hard drive in and copy everything over. But I suspect these small computers don't have room for a second drive. I should be able to plug both drives into another bigger machine that can take multiple drives and do the copy there.
It's always exciting (for a geek) to get a new machine. Of course, the part I'm trying not to think about is getting the new machine configured the way I want it and all my files moved over and software re-installed. Oh well, it's always a good opportunity to clean up and drop a lot of the junk you accumulate over time.
Labels:
hardware

Saturday, December 27, 2008
Nice UI Feature
Here's a screen shot of part of the Adobe Lightroom Export dialog:
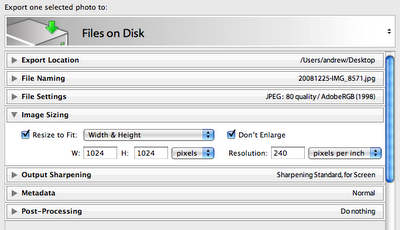 It consists of a bunch of sections that you can open and close. The part I like is that when they are closed they show a summary of the settings from that section. So you can leave sections closed but still see what you have chosen. Very nice. I haven't noticed this in any programs.
It consists of a bunch of sections that you can open and close. The part I like is that when they are closed they show a summary of the settings from that section. So you can leave sections closed but still see what you have chosen. Very nice. I haven't noticed this in any programs.
One minor criticism is that the "mode", in this case "Files on Disk" is chosen with the small, easily missed up/down arrow at the top right. I didn't figure this out for a while - I thought the only way to change it was to choose different presets (not shown in the screenshot)
The other thing I have trouble with when exporting is that I forget to select all the pictures. It does tell you at the top that it is only exporting one selected photo, but I always seem to miss this. But when it completes way faster than I expect, then I realize I forgot to select all the photos. Doh! It might be nice if the export dialog had a way to choose "All photos in collection" like the Slideshow module has.
Another nice part of Lightroom's export is that they have a facility for "plugins". I use Jeffrey Friedl's plugin for exporting to Google Picasa Web albums. There are also plugins for other things like Flickr.
 It consists of a bunch of sections that you can open and close. The part I like is that when they are closed they show a summary of the settings from that section. So you can leave sections closed but still see what you have chosen. Very nice. I haven't noticed this in any programs.
It consists of a bunch of sections that you can open and close. The part I like is that when they are closed they show a summary of the settings from that section. So you can leave sections closed but still see what you have chosen. Very nice. I haven't noticed this in any programs.One minor criticism is that the "mode", in this case "Files on Disk" is chosen with the small, easily missed up/down arrow at the top right. I didn't figure this out for a while - I thought the only way to change it was to choose different presets (not shown in the screenshot)
The other thing I have trouble with when exporting is that I forget to select all the pictures. It does tell you at the top that it is only exporting one selected photo, but I always seem to miss this. But when it completes way faster than I expect, then I realize I forgot to select all the photos. Doh! It might be nice if the export dialog had a way to choose "All photos in collection" like the Slideshow module has.
Another nice part of Lightroom's export is that they have a facility for "plugins". I use Jeffrey Friedl's plugin for exporting to Google Picasa Web albums. There are also plugins for other things like Flickr.
Labels:
lightroom,
user experience
Friday, December 26, 2008
Add Email Subscription to Blogger
It's hard to convince some people to use a feed reader like Google Reader. That includes some of my family. There had to be a better way than manually emailing them every time I posted! Besides, it never hurts to give people options to work the way they prefer.
I noticed an email widget on Seth Godin's blog from FeedBlitz. It's free for personal use and turned out to be fairly easy to add.
Here's how:
- go to feedblitz.com
- click on Try FeedBlitz Now! and sign up
- click on Forms and Widgets
- click on Email Subscription Widgets > New Blogger Widget
- enter your email address and the verification, then click on "Install Your Email Subscription Widget On Blogger"
- you may have to log in to Blogger if you're not already, then you should get to:
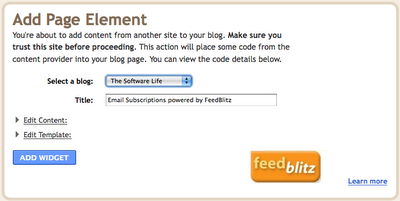
- choose Add Widget and you should get to your layout
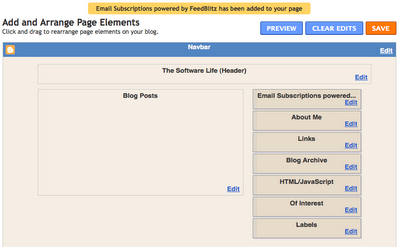
- look for a widget labeled "Email Subscriptions powered..." and drag it to where you want it
- to customize the appearance, choose Edit
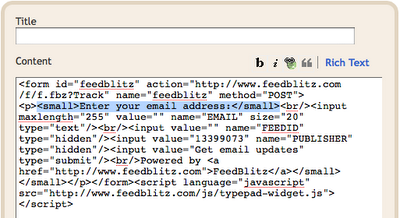
- I removed the Title and changed the code slightly. (Note: after removing the title it will show up in the layout as just "HTML/Javascript") Since you're getting the service for free, I figure it's only fair to leave the "Powered by FeedBlitz". Be careful not to change anything else.
- If it looks ok in Preview you can choose Save and you're finished. If you mess something up, just don't click Save.
I noticed an email widget on Seth Godin's blog from FeedBlitz. It's free for personal use and turned out to be fairly easy to add.
Here's how:
- go to feedblitz.com
- click on Try FeedBlitz Now! and sign up
- click on Forms and Widgets
- click on Email Subscription Widgets > New Blogger Widget
- enter your email address and the verification, then click on "Install Your Email Subscription Widget On Blogger"
- you may have to log in to Blogger if you're not already, then you should get to:

- choose Add Widget and you should get to your layout

- look for a widget labeled "Email Subscriptions powered..." and drag it to where you want it
- to customize the appearance, choose Edit

- I removed the Title and changed the code slightly. (Note: after removing the title it will show up in the layout as just "HTML/Javascript") Since you're getting the service for free, I figure it's only fair to leave the "Powered by FeedBlitz". Be careful not to change anything else.
- If it looks ok in Preview you can choose Save and you're finished. If you mess something up, just don't click Save.
Tuesday, December 23, 2008
jSuneido Slogging
Although I haven't been writing about it lately, I have been plugging away at jSuneido.
Once I could run the IDE (more or less) from jSuneido I could run the stdlib tests. Many of which, of course, failed.
So I've been fixing bugs, gradually getting tests to pass.
On a good day it's tedious and unglamorous. Any satisfaction from getting one test to pass is almost immediately extinguished as you move on to the next failing one. It's depressing being forced to confront all your screwups, one after another, for days on end.
On a bad day, like today, it's incredibly frustrating. I had the distinct urge to smash something, and honestly, I'm not usually the kind of person that wants to smash things.
It seemed like everything I touched broke umpteen other things. Things that used to work no longer worked. Eclipse wasn't working right, Parallels wasn't working right, my brain wasn't working right.
If it was someone else's code I could curse them and fantasize about how much better it would be if I had written it. But when it's your own code, and you've just finished rewriting it, the only conclusion you can draw is that you're an idiot!
The actually bugs, once I found them, haven't been major. Just stupid things like off by one errors. Quick, is Java Calendar MONTH zero based or one based? Many of them are incompatibilities between cSuneido and jSuneido (which is why my jSuneido tests didn't catch them).
Some of the date code worked in the morning but not in the afternoon. WTF! Guess what, Java Calendar HOUR is 12 hour, for 24 hour you need to use HOUR_OF_DAY. Argh! RTFM
I have about 20 tests still failing. Hopefully it won't take too many more days to clean them up.
Once I could run the IDE (more or less) from jSuneido I could run the stdlib tests. Many of which, of course, failed.
So I've been fixing bugs, gradually getting tests to pass.
On a good day it's tedious and unglamorous. Any satisfaction from getting one test to pass is almost immediately extinguished as you move on to the next failing one. It's depressing being forced to confront all your screwups, one after another, for days on end.
On a bad day, like today, it's incredibly frustrating. I had the distinct urge to smash something, and honestly, I'm not usually the kind of person that wants to smash things.
It seemed like everything I touched broke umpteen other things. Things that used to work no longer worked. Eclipse wasn't working right, Parallels wasn't working right, my brain wasn't working right.
If it was someone else's code I could curse them and fantasize about how much better it would be if I had written it. But when it's your own code, and you've just finished rewriting it, the only conclusion you can draw is that you're an idiot!
The actually bugs, once I found them, haven't been major. Just stupid things like off by one errors. Quick, is Java Calendar MONTH zero based or one based? Many of them are incompatibilities between cSuneido and jSuneido (which is why my jSuneido tests didn't catch them).
Some of the date code worked in the morning but not in the afternoon. WTF! Guess what, Java Calendar HOUR is 12 hour, for 24 hour you need to use HOUR_OF_DAY. Argh! RTFM
I have about 20 tests still failing. Hopefully it won't take too many more days to clean them up.
Thursday, December 18, 2008
Mac OS X + Epson R1800 = dark prints
I decided I should print some Christmas cards. But when I print the picture I want, it's way too dark. Argh!
This is an ongoing problem. The last batch of printing I did I settled on managing color on the printer (so I could make the following adjustments), setting the gamma to 1.5 (instead of 1.8 or 2.2), and cranking the brightness to the max of +25.
But even with those extreme adjustments, my current print was way too dark. (And it goes against most recommendations to manage color in the computer.)
Lots of other people have this problem (try Google). Leopard seems to have made the problem worse. Epson doesn't seem to want or be able to fix it. Nor are Apple or Adobe any help. On the other hand, it seems to work ok for some (many? most?) people. For some people the problem occurs in Lightroom but not Photoshop, but I get the same results from both.
A lot of the responses to this problem tell people it's because their monitor isn't calibrated. Maybe that's the case some of the time, but if my histogram is correct then the monitor has nothing to do with it. And I have the brightness on my 24" iMac turned down to the minimum. And the images look fine on other monitors as well.
Suggested "fixes" range from using the Gutenprint drivers (which don't support all the printer features) to reinstalling OS X (yikes!). Some people seem to have had success using the older version 3 driver.
I tried some of the common suggestions - deleting my Library/Printers/Epson folder, resetting the print subsystem, emptying the trash (?), restarting (just like Windows!), reinstaling the driver ... I did find there was an update to the 6.12 driver so I installed that as well.
I'm not sure how much difference it made. I now seem to be getting better results managing color on the computer (as most people recommend) rather than the printer. But I still had to adjust the image to the point of looking ugly on the screen (overexposing by .3) in order to get a decent print, which is something I really wanted to avoid. Maybe I can make a preset to make it easier to adjust for printing.
Judging from Google, there seem to be fewer problems with the newer R1900 but I really hate to replace a printer that has nothing physically wrong with it (AFAIK) , just to get around a software problem! And the R1800 isn't that old a model.
It's a frustrating problem because there are so many variables and it's very hard to objectively evaluate the results. I just changed the exposure from +.3 to +.5 making it lighter and I swear the print got slightly darker!
This is an ongoing problem. The last batch of printing I did I settled on managing color on the printer (so I could make the following adjustments), setting the gamma to 1.5 (instead of 1.8 or 2.2), and cranking the brightness to the max of +25.
But even with those extreme adjustments, my current print was way too dark. (And it goes against most recommendations to manage color in the computer.)
Lots of other people have this problem (try Google). Leopard seems to have made the problem worse. Epson doesn't seem to want or be able to fix it. Nor are Apple or Adobe any help. On the other hand, it seems to work ok for some (many? most?) people. For some people the problem occurs in Lightroom but not Photoshop, but I get the same results from both.
A lot of the responses to this problem tell people it's because their monitor isn't calibrated. Maybe that's the case some of the time, but if my histogram is correct then the monitor has nothing to do with it. And I have the brightness on my 24" iMac turned down to the minimum. And the images look fine on other monitors as well.
Suggested "fixes" range from using the Gutenprint drivers (which don't support all the printer features) to reinstalling OS X (yikes!). Some people seem to have had success using the older version 3 driver.
I tried some of the common suggestions - deleting my Library/Printers/Epson folder, resetting the print subsystem, emptying the trash (?), restarting (just like Windows!), reinstaling the driver ... I did find there was an update to the 6.12 driver so I installed that as well.
I'm not sure how much difference it made. I now seem to be getting better results managing color on the computer (as most people recommend) rather than the printer. But I still had to adjust the image to the point of looking ugly on the screen (overexposing by .3) in order to get a decent print, which is something I really wanted to avoid. Maybe I can make a preset to make it easier to adjust for printing.
Judging from Google, there seem to be fewer problems with the newer R1900 but I really hate to replace a printer that has nothing physically wrong with it (AFAIK) , just to get around a software problem! And the R1800 isn't that old a model.
It's a frustrating problem because there are so many variables and it's very hard to objectively evaluate the results. I just changed the exposure from +.3 to +.5 making it lighter and I swear the print got slightly darker!
Monday, December 15, 2008
Mac OS X on Asus Eee PC
http://www.maceee.com
I've been curious about the new "netbooks". I usually want a more powerful machine, even when traveling (e.g. to edit photos), but I like the idea of something small when I mainly want internet access. For that kind of use I'm not sure OS X is enough of a benefit to warrant the hacking. I think I'd be more tempted to use Linux if I wanted to avoid Windows.
I've been curious about the new "netbooks". I usually want a more powerful machine, even when traveling (e.g. to edit photos), but I like the idea of something small when I mainly want internet access. For that kind of use I'm not sure OS X is enough of a benefit to warrant the hacking. I think I'd be more tempted to use Linux if I wanted to avoid Windows.
Thursday, November 27, 2008
Burnt by ByteBuffer
In my last post about this, I had "solved" my ByteBuffer problem rather crudely, by setting the position back to zero. But I wasn't really happy with that - I figured I should know where the position was getting modified.
Strangely, the bug only showed up when I had debugging code in place. (Which is why the bug didn't show up until I put in debugging code to track down a different problem!) That told me that it was probably the debugging code itself that was changing the ByteBuffer position.
I started putting in asserts to check the position. The result baffled me at first. Here's what I had:
A classic example of why mutable state can cause problems. So not only does ByteBuffer burden you with this extra baggage, but it's also error prone baggage. Granted, it's my own fault for using it improperly.
The fix was easy. I quit using mark() and reset() and instead did:
I almost got burnt another way. I had used buf.rewind() to set the position back to zero. When I read the documentation more closely I found out that rewind() also clears the position saved by mark(). So if a nested method had called rewind() that would also have "broken" my use of mark/reset.
Oh well, I found the problem and fixed it, and now I know to be more careful. On to the next bug!
PS. It's annoying how Blogger loses the line spacing after any kind of block tag (like pre).
Strangely, the bug only showed up when I had debugging code in place. (Which is why the bug didn't show up until I put in debugging code to track down a different problem!) That told me that it was probably the debugging code itself that was changing the ByteBuffer position.
I started putting in asserts to check the position. The result baffled me at first. Here's what I had:
int pos = buf.position();Since mark() saves the position and reset() restores the position, I figured this should never fail. But it did! It turns out, what was happening was this:
buf.mark();
...
buf.reset();
assert(pos == buf.position());
method1: method2:The problem was that the nested mark() in method2 was overwriting the first mark(). So the outer reset() was restoring to the nested position, not to its own mark.
buf.mark();
... buf.mark();
method2(); ...
... buf.reset();
buf.reset();
A classic example of why mutable state can cause problems. So not only does ByteBuffer burden you with this extra baggage, but it's also error prone baggage. Granted, it's my own fault for using it improperly.
The fix was easy. I quit using mark() and reset() and instead did:
int pos = buf.position();That solved the problem.
...
buf.position(pos);
I almost got burnt another way. I had used buf.rewind() to set the position back to zero. When I read the documentation more closely I found out that rewind() also clears the position saved by mark(). So if a nested method had called rewind() that would also have "broken" my use of mark/reset.
Oh well, I found the problem and fixed it, and now I know to be more careful. On to the next bug!
PS. It's annoying how Blogger loses the line spacing after any kind of block tag (like pre).
Computers Not for Dummies
As much as we've progressed, computers still aren't always easy enough to use.
A few days ago I borrowed Shelley's Windows laptop to use to connect to my jSuneido server.
Of course, as soon as I fired it up it wanted to download and install updates, which I let it do. I thought I was being nice installing updates for her. But when I was done, the wireless wouldn't connect. It had been working fine up till then (that's how I got the updates). I just wrote it off to the usual unknown glitches and left it.
But the next day, Shelley tried to use the wireless and it still wouldn't connect. Oops, now I'm in trouble. I tried restarting the laptop and restarting the Time Capsule (equivalent to an Airport Extreme base station) but no luck. It was late in the evening so I gave up and left it for later.
Actually, the problem wasn't connecting - it would appear to connect just fine, but then it would "fail to acquire a network address" and disconnect. It would repeat this sequence endlessly.
I tried the usual highly skilled "messing around" that makes us techies appear so smart. I deleted the connection. I randomly changed the connection properties. Nothing worked.
Searching on the internet found some similar problems, but no solutions that worked for me.
One of the things I tried was turning off the security on the Time Capsule. That "solved" the problem - I could connect - but it obviously wasn't a good solution.
While I was connected I checked to see if there were any more Windows updates, figuring it was probably a Windows update that broke it, so maybe another Windows update would fix it. But there were no outstanding "critical" updates. Out of curiosity I checked the optional updates and found an update for the network interface driver. That seemed like it might be related.
Thankfully, that solved the problem. I turned the wireless security back on and I could still connect.
It still seems a little strange. Why did a Windows update require a new network interface driver? And if it did, why not make this a little more apparent. And why could it "connect" but not get an address? If the security was failing, couldn't it say that? And why does the hardware driver stop the security working? Is the security re-implemented in every driver? That doesn't make much sense.
But to get back to my original point, how would the average non-technical person figure out this kind of problem? Would they think to disable security temporarily (or connect with an actual cable) so they could look for optional updates that might help?
Of course, it's not an easy problem. I'd like to blame Microsoft for their troublesome update, but they have an almost infinite problem of trying to work with a huge range of third party hardware and drivers and software. Apple would argue that's one of the benefits of their maintaining control of the hardware, but I've had my share of weird problems on the Mac as well.
A few days ago I borrowed Shelley's Windows laptop to use to connect to my jSuneido server.
Of course, as soon as I fired it up it wanted to download and install updates, which I let it do. I thought I was being nice installing updates for her. But when I was done, the wireless wouldn't connect. It had been working fine up till then (that's how I got the updates). I just wrote it off to the usual unknown glitches and left it.
But the next day, Shelley tried to use the wireless and it still wouldn't connect. Oops, now I'm in trouble. I tried restarting the laptop and restarting the Time Capsule (equivalent to an Airport Extreme base station) but no luck. It was late in the evening so I gave up and left it for later.
Actually, the problem wasn't connecting - it would appear to connect just fine, but then it would "fail to acquire a network address" and disconnect. It would repeat this sequence endlessly.
I tried the usual highly skilled "messing around" that makes us techies appear so smart. I deleted the connection. I randomly changed the connection properties. Nothing worked.
Searching on the internet found some similar problems, but no solutions that worked for me.
One of the things I tried was turning off the security on the Time Capsule. That "solved" the problem - I could connect - but it obviously wasn't a good solution.
While I was connected I checked to see if there were any more Windows updates, figuring it was probably a Windows update that broke it, so maybe another Windows update would fix it. But there were no outstanding "critical" updates. Out of curiosity I checked the optional updates and found an update for the network interface driver. That seemed like it might be related.
Thankfully, that solved the problem. I turned the wireless security back on and I could still connect.
It still seems a little strange. Why did a Windows update require a new network interface driver? And if it did, why not make this a little more apparent. And why could it "connect" but not get an address? If the security was failing, couldn't it say that? And why does the hardware driver stop the security working? Is the security re-implemented in every driver? That doesn't make much sense.
But to get back to my original point, how would the average non-technical person figure out this kind of problem? Would they think to disable security temporarily (or connect with an actual cable) so they could look for optional updates that might help?
Of course, it's not an easy problem. I'd like to blame Microsoft for their troublesome update, but they have an almost infinite problem of trying to work with a huge range of third party hardware and drivers and software. Apple would argue that's one of the benefits of their maintaining control of the hardware, but I've had my share of weird problems on the Mac as well.
Wednesday, November 26, 2008
jSuneido Bugs
After I got to the point where I could start up the IDE on a Windows client from the jSuneido server, I thought it would be a short step to getting the test suite to run. (other than the tests that relied on rules and triggers which aren't implemented yet)
What I should have realized is that running the IDE, while impressive (to me, anyway), doesn't really exercise much of the server. It only involves simple queries, primarily just reading code from the database. Whereas the tests, obviously, exercise more features.
And so I've been plugging away getting the tests to pass, one by one, by fixing bugs in the server. Worthwhile work, just not very exciting.
Most of the bugs from yesterday resulted from me "improving" the code as I ported it from C++ to Java. The problem is, "improving" code that you don't fully understand is a dangerous game. Not surprisingly, I got burnt.
Coincidentally, almost all of yesterdays bugs related to mutable versus immutable data. The C++ code was treating certain data as immutable; it would create a new version rather than change the original. When I ported this code, I thought it would be easier/better to just change the original. The problem was that the data was shared, and changing the original affected all the places it was shared, instead of just the one place where I wanted a different version. Of course, in simple cases (like my tests!) the data wasn't shared and it worked fine.
Some of the other problems involved ByteBuffer. I'm using ByteBuffer as a "safe pointer" to a chunk of memory (which may be memory mapped to a part of the database file). But ByteBuffer has bunch of extra baggage, including a current "position", a "mark position", and a "limit". And it has a bunch of extra methods for dealing with these. It wouldn't be so bad if you could ignore these extras. But you can't, because even simple things like comparing buffers only compare based on the current "position". Of course, it's my own fault because obviously somewhere I'm doing something that changes that position. Bringing me back to the mutability issue.
For the most part I think that the Java libraries are reasonably well designed. Not perfect, but I've seen a lot worse. But for my purposes it would be better if there was a lighter weight "base" version of ByteBuffer without all the extras.
I can see someone saying that I'm "misusing" ByteBuffer, that since I'm coming from C/C++ and I'm trying to get back my beloved pointers. But I don't think that's the case. The reason for using ByteBuffer this way is that it's the only way to handle memory mapped files.
I guess one option would be to limit the use of ByteBuffer to just the memory mapped file io, and to copy the data (e.g. into byte arrays) to use everywhere else. But having to copy everything kind of defeats the purpose of using memory mapped access. Not to mention it would require major surgery on the code :-(
What I should have realized is that running the IDE, while impressive (to me, anyway), doesn't really exercise much of the server. It only involves simple queries, primarily just reading code from the database. Whereas the tests, obviously, exercise more features.
And so I've been plugging away getting the tests to pass, one by one, by fixing bugs in the server. Worthwhile work, just not very exciting.
Most of the bugs from yesterday resulted from me "improving" the code as I ported it from C++ to Java. The problem is, "improving" code that you don't fully understand is a dangerous game. Not surprisingly, I got burnt.
Coincidentally, almost all of yesterdays bugs related to mutable versus immutable data. The C++ code was treating certain data as immutable; it would create a new version rather than change the original. When I ported this code, I thought it would be easier/better to just change the original. The problem was that the data was shared, and changing the original affected all the places it was shared, instead of just the one place where I wanted a different version. Of course, in simple cases (like my tests!) the data wasn't shared and it worked fine.
Some of the other problems involved ByteBuffer. I'm using ByteBuffer as a "safe pointer" to a chunk of memory (which may be memory mapped to a part of the database file). But ByteBuffer has bunch of extra baggage, including a current "position", a "mark position", and a "limit". And it has a bunch of extra methods for dealing with these. It wouldn't be so bad if you could ignore these extras. But you can't, because even simple things like comparing buffers only compare based on the current "position". Of course, it's my own fault because obviously somewhere I'm doing something that changes that position. Bringing me back to the mutability issue.
For the most part I think that the Java libraries are reasonably well designed. Not perfect, but I've seen a lot worse. But for my purposes it would be better if there was a lighter weight "base" version of ByteBuffer without all the extras.
I can see someone saying that I'm "misusing" ByteBuffer, that since I'm coming from C/C++ and I'm trying to get back my beloved pointers. But I don't think that's the case. The reason for using ByteBuffer this way is that it's the only way to handle memory mapped files.
I guess one option would be to limit the use of ByteBuffer to just the memory mapped file io, and to copy the data (e.g. into byte arrays) to use everywhere else. But having to copy everything kind of defeats the purpose of using memory mapped access. Not to mention it would require major surgery on the code :-(
Monday, November 24, 2008
More on Why jSuneido
A recent post by Charles Nutter (the main guy for jRuby) reiterates the advantages of running a language on top of the Java virtual machine.
Thursday, November 20, 2008
jSuneido Slow on OS X - Fixed
Thankfully, I found the problem. Apart from the time wasted, it's somewhat amusing because I was circling around the problem/solution but not quite hitting it.
My first thought was that it was Parallels but I quickly eliminated that.
My next thought was that it was a network issue but if I just did a sequence of invalid commands it was fast.
I woke up in the middle of the night and thought maybe it's the Nagle/Ack problem, and if so, an invalid command wouldn't trigger it because it does a single write. But when I replaced the database calls with stubs (but still doing similar network IO) it was fast, pointing back to the database code.
Ok, maybe it's the memory mapping. I could see that possibly differing between OS X and Windows. But when I swapped out the memory mapping for an in-memory testing version it was still slow.
This isn't making any sense. I still think it seems like a network thing.
I stub out the database calls and it's fast again, implying it's not the network. But in my stubs I'm returning a fixed size record instead of varying sizes like the database would. I change it to return a random size up to 1000 bytes. It's still fast. For no good reason, I change it to up to 2000 bytes and it's slow!
I seem to recall TCP/IP packet size being around 1400 bytes so that's awfully suspicious.
I insert client.socket().setTcpNoDelay(true) into the network server code I'm using and sure enough that solves the problem. (Actually first time around I set it to false, getting confused by the double negative.)
A better solution might be to use gathering writes, but at this point I don't want to get distracted trying to implement this in someone else's code.
This doesn't explain why the problem only showed up on OS X and not on Windows. There must be some difference in the TCP/IP implementation.
In any case, I'm happy to have solved the problem. Now I can get back to work after a several day detour.
My first thought was that it was Parallels but I quickly eliminated that.
My next thought was that it was a network issue but if I just did a sequence of invalid commands it was fast.
I woke up in the middle of the night and thought maybe it's the Nagle/Ack problem, and if so, an invalid command wouldn't trigger it because it does a single write. But when I replaced the database calls with stubs (but still doing similar network IO) it was fast, pointing back to the database code.
Ok, maybe it's the memory mapping. I could see that possibly differing between OS X and Windows. But when I swapped out the memory mapping for an in-memory testing version it was still slow.
This isn't making any sense. I still think it seems like a network thing.
I stub out the database calls and it's fast again, implying it's not the network. But in my stubs I'm returning a fixed size record instead of varying sizes like the database would. I change it to return a random size up to 1000 bytes. It's still fast. For no good reason, I change it to up to 2000 bytes and it's slow!
I seem to recall TCP/IP packet size being around 1400 bytes so that's awfully suspicious.
I insert client.socket().setTcpNoDelay(true) into the network server code I'm using and sure enough that solves the problem. (Actually first time around I set it to false, getting confused by the double negative.)
A better solution might be to use gathering writes, but at this point I don't want to get distracted trying to implement this in someone else's code.
This doesn't explain why the problem only showed up on OS X and not on Windows. There must be some difference in the TCP/IP implementation.
In any case, I'm happy to have solved the problem. Now I can get back to work after a several day detour.
Tuesday, November 18, 2008
jSuneido Slow on OS X
The slowness of jSuneido isn't because of running through Parallels. I tried running the client on two external Windows machines with the same slow results as with Parallels.
Next, in order to eliminate Eclipse as the problem, I figured out how to package jSuneido into a jar file, which turned out to be a simple matter of using Export from Eclipse.
However, when I tried to run the jar file outside Eclipse under OS X, I got an error:
java.lang.NoClassDefFoundError: java/util/ArrayDeque
At first I assumed this was some kind of classpath issue. But after messing with that for a bit I finally realized that it was because the default Java version on OS X is 1.5 and ArrayDeque was introduced in 6 (aka 1.6).
From the web it seems that Java 6 is not well supported on the Mac. Apple has an update to get it, but it still leaves the default as Java 1.5 And the update is only for 64 bit. I didn't come across any good explanation of why Apple is dragging it's feet with Java 6.
I actually already had Java 6 installed since that was what I was using in Eclipse. (Which is why it was working there.)
But ... same problem, painfully slow, running the jar file outside Eclipse (but still on OS X)
Running the jar file on Windows under Parallels was fast, so the problem isn't the Mac hardware (not that I thought it would be).
I'd like to try running jSuneido under Java 1.5 to see if that works any better (since it is the OS X default). But in addition to Deque (which I could probably replace fairly easily) I'm also using methods of TreeMap and TreeSet that aren't available.
What's annoying is that I thought I was protected from this because of the compliance settings in Eclipse:
 Maybe I'm misinterpreting these settings, but I expected it to warn me if my code wasn't compatible with Java 1.5
Maybe I'm misinterpreting these settings, but I expected it to warn me if my code wasn't compatible with Java 1.5
So far this doesn't leave me with any good options
- I can run slowly from Eclipse - yuck
- I can package a jar file and copy it to Windows - a slow edit-build-test cycle - yuck
- I can install Eclipse on Windows under Parallels and do all my work there - defeating the purpose of having a Mac - yuck
The real question is still why jSuneido is so slow running on OS X. I assume it's something specific in my code or there would be a lot more complaints. But what? Memory mapping? NIO? And how do I figure it out? Profile? Maybe there are some Java options that would help?
PS. I should mention that it's a major difference in speed, roughly 20x
Next, in order to eliminate Eclipse as the problem, I figured out how to package jSuneido into a jar file, which turned out to be a simple matter of using Export from Eclipse.
However, when I tried to run the jar file outside Eclipse under OS X, I got an error:
java.lang.NoClassDefFoundError: java/util/ArrayDeque
At first I assumed this was some kind of classpath issue. But after messing with that for a bit I finally realized that it was because the default Java version on OS X is 1.5 and ArrayDeque was introduced in 6 (aka 1.6).
From the web it seems that Java 6 is not well supported on the Mac. Apple has an update to get it, but it still leaves the default as Java 1.5 And the update is only for 64 bit. I didn't come across any good explanation of why Apple is dragging it's feet with Java 6.
I actually already had Java 6 installed since that was what I was using in Eclipse. (Which is why it was working there.)
But ... same problem, painfully slow, running the jar file outside Eclipse (but still on OS X)
Running the jar file on Windows under Parallels was fast, so the problem isn't the Mac hardware (not that I thought it would be).
I'd like to try running jSuneido under Java 1.5 to see if that works any better (since it is the OS X default). But in addition to Deque (which I could probably replace fairly easily) I'm also using methods of TreeMap and TreeSet that aren't available.
What's annoying is that I thought I was protected from this because of the compliance settings in Eclipse:
 Maybe I'm misinterpreting these settings, but I expected it to warn me if my code wasn't compatible with Java 1.5
Maybe I'm misinterpreting these settings, but I expected it to warn me if my code wasn't compatible with Java 1.5So far this doesn't leave me with any good options
- I can run slowly from Eclipse - yuck
- I can package a jar file and copy it to Windows - a slow edit-build-test cycle - yuck
- I can install Eclipse on Windows under Parallels and do all my work there - defeating the purpose of having a Mac - yuck
The real question is still why jSuneido is so slow running on OS X. I assume it's something specific in my code or there would be a lot more complaints. But what? Memory mapping? NIO? And how do I figure it out? Profile? Maybe there are some Java options that would help?
PS. I should mention that it's a major difference in speed, roughly 20x
Monday, November 17, 2008
Thank Goodness
I was excited when I got to the point where I could start up a Suneido client from my Java Suneido server.
But ... as I soon realized, it was painfully slow. I wasn't panicking since it's still early stages, but it was nagging me. What if, like many people say, Java is just too slow?
I kept forgetting to try it at work on my Windows PC since at home I'm going though the Parallels virtual machine.
Finally I remembered, and ... big sigh of relief ... it's fast on my Windows PC. I haven't done any benchmarks but starting up the IDE seems roughly the same as with the cSuneido server.
I'm not quite sure why it's so slow with Parallels - that's a bit of a nuisance since I work on this mostly at home on my Mac. Maybe something to do with the networking? But at least I don't have a major speed issue (yet).
I'm also still running jSuneido from within Eclipse. That might make a difference too. One of these days I'll have to figure out how to run it outside the IDE!
But ... as I soon realized, it was painfully slow. I wasn't panicking since it's still early stages, but it was nagging me. What if, like many people say, Java is just too slow?
I kept forgetting to try it at work on my Windows PC since at home I'm going though the Parallels virtual machine.
Finally I remembered, and ... big sigh of relief ... it's fast on my Windows PC. I haven't done any benchmarks but starting up the IDE seems roughly the same as with the cSuneido server.
I'm not quite sure why it's so slow with Parallels - that's a bit of a nuisance since I work on this mostly at home on my Mac. Maybe something to do with the networking? But at least I don't have a major speed issue (yet).
I'm also still running jSuneido from within Eclipse. That might make a difference too. One of these days I'll have to figure out how to run it outside the IDE!
Sunday, November 16, 2008
Flailing with Parallels 4
The new version of Parallels is out. I bought it, downloaded it, and installed it. They've changed the virtual machine format so you have to convert them. The slowest part of this process was making a backup (my Windows Vista VM is over 100 gb).
Everything worked fine, and I should have left well enough alone, but during the upgrade process I noticed that my 30 gb virtual disk file was 80 gb. So I thought I'd try the Compressor tool. (I'd never used it before.)
I got this message:
Parallels Compressor is unable to compress the virtual disk files,
because the virtual machine has snapshots, or its disks are either
plain disks or undo disks. If you want to compress the virtual disk
file(s), delete all snapshots using Snapshot Manager and/or disable
undo disks in the Configuration Editor.
So I opened the Snapshot Manager and started deleting. I deleted the most recent one, but when I tried to delete the next one it froze. I waited a while, but nothing seemed to be happening and the first deletion had been quick. I ended up force quitting Parallels, although I hated doing this when my virtual machine was running since that's caused problems in the past.
But when I restarted Parallels it was still "stuck". Most of the menu options were grayed out. When I tried to quit I got:
Cannot close the virtual machine window.
The operation of deleting a virtual machine snapshot is currently in
progress. Wait until it is complete and try again.
I force quit Parallels again. I tried deleting the snapshot files but that didn't help. Force quit again.
I had, thankfully, backed up the upgraded vm before these problems. But it took an hour or more to copy the 100 gb to or from my Time Capsule. (That seems slow for a hardwired network connection, but I guess it is a lot of data.) So first I tried to restore just some of the smaller files, figuring the big disk images were probably ok. This didn't help.
Next I tried deleting the Parallels directory from my Library directory, thinking that might be where it had stored the fact that it was trying to delete a snapshot. This didn't help either.
So I bit the bullet and copied the entire vm from the backup. An hour later I start Parallels again, only to find nothing has changed - same problem. Where the heck is the problem?
The only other thing I can think of is the application itself so I start reinstalling. Part way through I get a message to please quit the Parallels virtual machine. But it's not running??? I look at the running processes and sure enough there's a Parallels process. Argh!
In hindsight, the message that "an operation" was "in progress" should have been enough of a clue. But I just assumed that force quitting the application would kill all of its processes. I'm not sure why it didn't. Maybe Parallels "detached" this process for some reason? I also jumped to the (incorrect) conclusion that there was a "flag" set somewhere that was making it think the operation was in progress.
If this had been on Windows, one of the first things I would have tried is rebooting, which would have fixed this. But I'm not used to having to do that on OS X. I probably didn't need to reboot this time either, killing the leftover process likely would have been sufficient. But just to be safe I did.
Sure enough, that solved the problem, albeit after wasting several hours. Once more, now that everything was functional, I should have left well enough alone, but I can be stubborn and I still had that oversize disk image.
This time I shut down the virtual machine before using the Snapshot Manager and I had no problems deleting the snapshots.
But when I restart the vm and run Compressor, I get exactly the same message. I have no snapshots, and "undo disks" is disabled. I'm not sure what "plain" disks are, but mine are "expandable" (which is actually a misleading name since they have a fixed maximum size) and the help says I should be able to compress expandable drives. I have no idea why it refuses to work.
While I'm in the help I see you can also compress drives with the Image Tools so I try that and finally I have success. My disk image file is now down to 30 gb. I'm not sure it was worth the stress though!
Everything worked fine, and I should have left well enough alone, but during the upgrade process I noticed that my 30 gb virtual disk file was 80 gb. So I thought I'd try the Compressor tool. (I'd never used it before.)
I got this message:
Parallels Compressor is unable to compress the virtual disk files,
because the virtual machine has snapshots, or its disks are either
plain disks or undo disks. If you want to compress the virtual disk
file(s), delete all snapshots using Snapshot Manager and/or disable
undo disks in the Configuration Editor.
So I opened the Snapshot Manager and started deleting. I deleted the most recent one, but when I tried to delete the next one it froze. I waited a while, but nothing seemed to be happening and the first deletion had been quick. I ended up force quitting Parallels, although I hated doing this when my virtual machine was running since that's caused problems in the past.
But when I restarted Parallels it was still "stuck". Most of the menu options were grayed out. When I tried to quit I got:
Cannot close the virtual machine window.
The operation of deleting a virtual machine snapshot is currently in
progress. Wait until it is complete and try again.
I force quit Parallels again. I tried deleting the snapshot files but that didn't help. Force quit again.
I had, thankfully, backed up the upgraded vm before these problems. But it took an hour or more to copy the 100 gb to or from my Time Capsule. (That seems slow for a hardwired network connection, but I guess it is a lot of data.) So first I tried to restore just some of the smaller files, figuring the big disk images were probably ok. This didn't help.
Next I tried deleting the Parallels directory from my Library directory, thinking that might be where it had stored the fact that it was trying to delete a snapshot. This didn't help either.
So I bit the bullet and copied the entire vm from the backup. An hour later I start Parallels again, only to find nothing has changed - same problem. Where the heck is the problem?
The only other thing I can think of is the application itself so I start reinstalling. Part way through I get a message to please quit the Parallels virtual machine. But it's not running??? I look at the running processes and sure enough there's a Parallels process. Argh!
In hindsight, the message that "an operation" was "in progress" should have been enough of a clue. But I just assumed that force quitting the application would kill all of its processes. I'm not sure why it didn't. Maybe Parallels "detached" this process for some reason? I also jumped to the (incorrect) conclusion that there was a "flag" set somewhere that was making it think the operation was in progress.
If this had been on Windows, one of the first things I would have tried is rebooting, which would have fixed this. But I'm not used to having to do that on OS X. I probably didn't need to reboot this time either, killing the leftover process likely would have been sufficient. But just to be safe I did.
Sure enough, that solved the problem, albeit after wasting several hours. Once more, now that everything was functional, I should have left well enough alone, but I can be stubborn and I still had that oversize disk image.
This time I shut down the virtual machine before using the Snapshot Manager and I had no problems deleting the snapshots.
But when I restart the vm and run Compressor, I get exactly the same message. I have no snapshots, and "undo disks" is disabled. I'm not sure what "plain" disks are, but mine are "expandable" (which is actually a misleading name since they have a fixed maximum size) and the help says I should be able to compress expandable drives. I have no idea why it refuses to work.
While I'm in the help I see you can also compress drives with the Image Tools so I try that and finally I have success. My disk image file is now down to 30 gb. I'm not sure it was worth the stress though!
Saturday, November 15, 2008
Library Software Sucks
Every so often I decide I should use the library more, instead of buying quite so many books. Since the books I want are almost always out or at another branch, I don't go to the library in person much. Instead, I use their web interface.
First, I guess I should be grateful / thankful that they have a web interface at all.
But it could be so much better!
I'm going to compare to Amazon, not because Amazon is necessarily perfect, but it's pretty good and most people are familiar with it.
Obviously, I'm talking about the web interface for my local library. There could be better systems out there, but I suspect most of them are just as bad.
 Amazon has a Search box on every page. The library forces you to go to a separate search page. Although "Keyword Search" is probably what you want, it's on the right. On the left, where you naturally tend to go first, is "Exact Search". Except it's not exactly "exact", since they carefully put instructions on the screen to drop "the", "a", "an" from the beginning. This kind of thing drives me crazy. Why can't the software do that automatically? (It's like almost every site that takes a credit card number wants you to omit the spaces, even though it could do that trivially for you.) However, they don't tell you equally or more important tips like if you're searching for an author you have to enter last name first.
Amazon has a Search box on every page. The library forces you to go to a separate search page. Although "Keyword Search" is probably what you want, it's on the right. On the left, where you naturally tend to go first, is "Exact Search". Except it's not exactly "exact", since they carefully put instructions on the screen to drop "the", "a", "an" from the beginning. This kind of thing drives me crazy. Why can't the software do that automatically? (It's like almost every site that takes a credit card number wants you to omit the spaces, even though it could do that trivially for you.) However, they don't tell you equally or more important tips like if you're searching for an author you have to enter last name first.
Assuming you're paying attention enough to realize you want the keyword search, you now have to read the fine print:
 Oops. I guess I was too slow. I'm not sure what session it's talking about since I didn't log in. When I click on "begin a new session" it takes me back to the Search screen, with my search gone, of course.
Oops. I guess I was too slow. I'm not sure what session it's talking about since I didn't log in. When I click on "begin a new session" it takes me back to the Search screen, with my search gone, of course.
Let's try "edward abbey" - 7 results including some about him or with prefaces by him.
How about "abbey, edward" - 5 results including one by "Carpenter, Edward" called "Westminster Abby". So much for exact phrase. Maybe the comma?
Try "abbey edward" - same results so I'm not sure what they mean by "exact phrase"
 The search results themselves could be a lot nicer. No cover images. And nothing to make the title stand out. And the titles are all lower case. That may be how librarians treat them, but it's not how anyone else writes titles.
The search results themselves could be a lot nicer. No cover images. And nothing to make the title stand out. And the titles are all lower case. That may be how librarians treat them, but it's not how anyone else writes titles.
 Oops, sat on the search results screen too long. At least this time it didn't talk about my session.
Oops, sat on the search results screen too long. At least this time it didn't talk about my session.
Back on the search results, there's a check box to add to "My Hitlist". When I first saw that I was excited. Then I read that the list disappears when my "session" ends. Since my "session" seems to get abrubtly ended fairly regularly, the hitlist doesn't appear too useful.
It would be really nice if you could have persistent "wish lists" like on Amazon.
Once you find a book you can reserve it. That's great and it's the whole reason I'm on here. But it presents you with a bit of a dilemma. If you reserve a bunch of books, they tend to arrive in bunches, and you can't read them all before they're due back. But if you only reserve one or two, then you could be waiting a month or two to get them.
Ideally, I'd like to see something like Rogers Video Direct, where I can add as many movies as I want to my "Zip List" (where do they come up with these names?) and they send me three at a time as they become available. When I return one then they send me another.
 Notice the "Log Out" on the top right. This is a strange one since there's no "Log In". It seems to take you to the same screen as when your "session" times out. The only way to log in that I've found is to choose "My Account", which then opens a new window. This window doesn't have a Log Out link, instead it tells you to close the window when you're finished by clicking the "X" in the top right corner. Of course, I'm on a Max so my "X" is in the top left. But that's not a problem because if you stay in the My Account window too long (a minute or so) it closes itself.
Notice the "Log Out" on the top right. This is a strange one since there's no "Log In". It seems to take you to the same screen as when your "session" times out. The only way to log in that I've found is to choose "My Account", which then opens a new window. This window doesn't have a Log Out link, instead it tells you to close the window when you're finished by clicking the "X" in the top right corner. Of course, I'm on a Max so my "X" is in the top left. But that's not a problem because if you stay in the My Account window too long (a minute or so) it closes itself.
Of course, this assumes you didn't delay too long in clicking on My Account, because then you'll get:
 Obviously, the lesson here is that you better not dither. But why? The reason the web scales is that once I've downloaded a page, I can sit and look at it as long as I like, without requiring any additional effort from the server. I'm not sure why this library system is so intent on getting rid of me. I could see if it was storing a bunch of session data for me that it might just be over aggressive about purging sessions. But I'm just browsing, it should be stateless as far as the server is concerned.
Obviously, the lesson here is that you better not dither. But why? The reason the web scales is that once I've downloaded a page, I can sit and look at it as long as I like, without requiring any additional effort from the server. I'm not sure why this library system is so intent on getting rid of me. I could see if it was storing a bunch of session data for me that it might just be over aggressive about purging sessions. But I'm just browsing, it should be stateless as far as the server is concerned.
And then there's the quality of the data itself. I'd show you some examples, but:
 I've tried reporting errors in the data, like author's name duplicated or mis-spelled but there doesn't seem to be any process for users to report errors. It'd be nice if users could simply mark possible errors as they were browsing so library staff could clean them up.
I've tried reporting errors in the data, like author's name duplicated or mis-spelled but there doesn't seem to be any process for users to report errors. It'd be nice if users could simply mark possible errors as they were browsing so library staff could clean them up.
I could go on longer - what about new releases? what about suggestions based on my previous selections? what about a history of the books I've borrowed? what about reviews? Amazon has all these. But I'm sure by now you get the point.
I suspect the public web interface is an afterthought that didn't get much attention. And it's a case where the buyers (the libraries/librarians) aren't the end users (of the public web interface anyway). And since these are huge expensive systems there's large amounts of inertia. Even if something better did come along it would be an uphill battle to get libraries to switch.
And it's unlikely any complaints or suggestions from users even get back to the software developers. There are too many layers in between. I've tried to politely suggest the software could be better but all I get is a blank look and an offer to teach me how to use it. After all, I should be grateful, it's not that long ago we had to search a paper card catalog. I'm afraid at this rate it's not likely to improve very quickly.
The copyright at the bottom reads:
First, I guess I should be grateful / thankful that they have a web interface at all.
But it could be so much better!
I'm going to compare to Amazon, not because Amazon is necessarily perfect, but it's pretty good and most people are familiar with it.
Obviously, I'm talking about the web interface for my local library. There could be better systems out there, but I suspect most of them are just as bad.
 Amazon has a Search box on every page. The library forces you to go to a separate search page. Although "Keyword Search" is probably what you want, it's on the right. On the left, where you naturally tend to go first, is "Exact Search". Except it's not exactly "exact", since they carefully put instructions on the screen to drop "the", "a", "an" from the beginning. This kind of thing drives me crazy. Why can't the software do that automatically? (It's like almost every site that takes a credit card number wants you to omit the spaces, even though it could do that trivially for you.) However, they don't tell you equally or more important tips like if you're searching for an author you have to enter last name first.
Amazon has a Search box on every page. The library forces you to go to a separate search page. Although "Keyword Search" is probably what you want, it's on the right. On the left, where you naturally tend to go first, is "Exact Search". Except it's not exactly "exact", since they carefully put instructions on the screen to drop "the", "a", "an" from the beginning. This kind of thing drives me crazy. Why can't the software do that automatically? (It's like almost every site that takes a credit card number wants you to omit the spaces, even though it could do that trivially for you.) However, they don't tell you equally or more important tips like if you're searching for an author you have to enter last name first.Assuming you're paying attention enough to realize you want the keyword search, you now have to read the fine print:
Searching by "Keyword" searches all indexed fields. Use the words and, or, and not to combine words to limit or broaden a search. If you enter more than one word without and, or, or not, then your keywords will be searched as an exact phrase.Since they don't tell you which fields are indexed the first sentence is useless. The last sentence is surprising. Why would you make the default searching by "exact phrase". If you wanted "exact" wouldn't you be using the exact search on the left?
 Oops. I guess I was too slow. I'm not sure what session it's talking about since I didn't log in. When I click on "begin a new session" it takes me back to the Search screen, with my search gone, of course.
Oops. I guess I was too slow. I'm not sure what session it's talking about since I didn't log in. When I click on "begin a new session" it takes me back to the Search screen, with my search gone, of course.Let's try "edward abbey" - 7 results including some about him or with prefaces by him.
How about "abbey, edward" - 5 results including one by "Carpenter, Edward" called "Westminster Abby". So much for exact phrase. Maybe the comma?
Try "abbey edward" - same results so I'm not sure what they mean by "exact phrase"
 The search results themselves could be a lot nicer. No cover images. And nothing to make the title stand out. And the titles are all lower case. That may be how librarians treat them, but it's not how anyone else writes titles.
The search results themselves could be a lot nicer. No cover images. And nothing to make the title stand out. And the titles are all lower case. That may be how librarians treat them, but it's not how anyone else writes titles. Oops, sat on the search results screen too long. At least this time it didn't talk about my session.
Oops, sat on the search results screen too long. At least this time it didn't talk about my session.Back on the search results, there's a check box to add to "My Hitlist". When I first saw that I was excited. Then I read that the list disappears when my "session" ends. Since my "session" seems to get abrubtly ended fairly regularly, the hitlist doesn't appear too useful.
It would be really nice if you could have persistent "wish lists" like on Amazon.
Once you find a book you can reserve it. That's great and it's the whole reason I'm on here. But it presents you with a bit of a dilemma. If you reserve a bunch of books, they tend to arrive in bunches, and you can't read them all before they're due back. But if you only reserve one or two, then you could be waiting a month or two to get them.
Ideally, I'd like to see something like Rogers Video Direct, where I can add as many movies as I want to my "Zip List" (where do they come up with these names?) and they send me three at a time as they become available. When I return one then they send me another.
 Notice the "Log Out" on the top right. This is a strange one since there's no "Log In". It seems to take you to the same screen as when your "session" times out. The only way to log in that I've found is to choose "My Account", which then opens a new window. This window doesn't have a Log Out link, instead it tells you to close the window when you're finished by clicking the "X" in the top right corner. Of course, I'm on a Max so my "X" is in the top left. But that's not a problem because if you stay in the My Account window too long (a minute or so) it closes itself.
Notice the "Log Out" on the top right. This is a strange one since there's no "Log In". It seems to take you to the same screen as when your "session" times out. The only way to log in that I've found is to choose "My Account", which then opens a new window. This window doesn't have a Log Out link, instead it tells you to close the window when you're finished by clicking the "X" in the top right corner. Of course, I'm on a Max so my "X" is in the top left. But that's not a problem because if you stay in the My Account window too long (a minute or so) it closes itself.Of course, this assumes you didn't delay too long in clicking on My Account, because then you'll get:
 Obviously, the lesson here is that you better not dither. But why? The reason the web scales is that once I've downloaded a page, I can sit and look at it as long as I like, without requiring any additional effort from the server. I'm not sure why this library system is so intent on getting rid of me. I could see if it was storing a bunch of session data for me that it might just be over aggressive about purging sessions. But I'm just browsing, it should be stateless as far as the server is concerned.
Obviously, the lesson here is that you better not dither. But why? The reason the web scales is that once I've downloaded a page, I can sit and look at it as long as I like, without requiring any additional effort from the server. I'm not sure why this library system is so intent on getting rid of me. I could see if it was storing a bunch of session data for me that it might just be over aggressive about purging sessions. But I'm just browsing, it should be stateless as far as the server is concerned.And then there's the quality of the data itself. I'd show you some examples, but:
 I've tried reporting errors in the data, like author's name duplicated or mis-spelled but there doesn't seem to be any process for users to report errors. It'd be nice if users could simply mark possible errors as they were browsing so library staff could clean them up.
I've tried reporting errors in the data, like author's name duplicated or mis-spelled but there doesn't seem to be any process for users to report errors. It'd be nice if users could simply mark possible errors as they were browsing so library staff could clean them up.I could go on longer - what about new releases? what about suggestions based on my previous selections? what about a history of the books I've borrowed? what about reviews? Amazon has all these. But I'm sure by now you get the point.
I suspect the public web interface is an afterthought that didn't get much attention. And it's a case where the buyers (the libraries/librarians) aren't the end users (of the public web interface anyway). And since these are huge expensive systems there's large amounts of inertia. Even if something better did come along it would be an uphill battle to get libraries to switch.
And it's unlikely any complaints or suggestions from users even get back to the software developers. There are too many layers in between. I've tried to politely suggest the software could be better but all I get is a blank look and an offer to teach me how to use it. After all, I should be grateful, it's not that long ago we had to search a paper card catalog. I'm afraid at this rate it's not likely to improve very quickly.
The copyright at the bottom reads:
Copyright © Sirsi-Dynix. All rights reserved.
Version 2003.1.3 (Build 405.8)
I wonder if that means this version of the software is from 2003. Five years is a long time in the software business. Either the library isn't buying the updates, or Sirsi-Dynix is a tad behind on their development. But hey, their web site says "SirsiDynix is the global leader in strategic technology solutions for libraries". If so, technology solutions for libraries are in a pretty sad state.
Friday, November 14, 2008
Wikipedia on the iPhone and iPod Touch
I recently stumbled across an offline Wikipedia for the iPhone and iPod Touch. I don't have either, but Shelley has an iPod touch so I installed it there. It wasn't free but it was less than $10. You buy the app from the iTunes store and then when you run it for the first time it downloads the actual Wikipedia. It's 2gb so it takes a while. (and uses up space)
I had a copy of Wikipedia on my Palm and since I drifted away from using/carrying my Palm it's one of the few things I miss.
This version doesn't have any images, but otherwise it seems pretty good. The searching isn't the greatest, for example Elbrus and Mt Elbrus didn't find anything, but Mount Elbrus did.
I'm not sure exactly why I love having an encyclopedia at my fingertips. But there's something about having so much "knowledge" in your pocket. I'm just naturally curious I guess.
Despite trying to cut down on my gadget addiction, this adds another justification for buying an iPhone or iPod Touch. I hate the monthly fees and long term contracts with the iPhone, but it's definitely a more versatile gadget.
I had a copy of Wikipedia on my Palm and since I drifted away from using/carrying my Palm it's one of the few things I miss.
This version doesn't have any images, but otherwise it seems pretty good. The searching isn't the greatest, for example Elbrus and Mt Elbrus didn't find anything, but Mount Elbrus did.
I'm not sure exactly why I love having an encyclopedia at my fingertips. But there's something about having so much "knowledge" in your pocket. I'm just naturally curious I guess.
Despite trying to cut down on my gadget addiction, this adds another justification for buying an iPhone or iPod Touch. I hate the monthly fees and long term contracts with the iPhone, but it's definitely a more versatile gadget.
Wednesday, November 12, 2008
Lightroom and Lua
I'm a fan of Adobe Lightroom. It has a great user interface - understated elegance and smooth user experience. And it does a great job, it's fast, and it's relatively small.
I knew Lightroom used Lua, for example in plugins. But I was surprised when I came across a presentation that said 63% of Lightroom specific code is written in Lua (with the remainder in C, Objective C, and C++).
That's impressive. Many people would assume that a program written in a "scripting" language would be slow and ugly. That might be true of many programs (scripting language or not!) but I think this proves otherwise.
I also find it reassuring because, in a sense, it validates the approach we took in writing our trucking software. We wrote it in Suneido (comparable to a scripting language) for many of the same reasons Adobe wrote Lightroom in Lua.
Of course, the difference is that they chose an existing language, whereas I wrote Suneido. I would not have been as impressed if Adobe had chosen to write their own scripting language. Of course, that raises the question whether we should have used an existing language to write our trucking software. If I was starting today, I might say yes, but given the situation when we started (years ago) I'm not sure I'd do it any differently.
I knew Lightroom used Lua, for example in plugins. But I was surprised when I came across a presentation that said 63% of Lightroom specific code is written in Lua (with the remainder in C, Objective C, and C++).
That's impressive. Many people would assume that a program written in a "scripting" language would be slow and ugly. That might be true of many programs (scripting language or not!) but I think this proves otherwise.
I also find it reassuring because, in a sense, it validates the approach we took in writing our trucking software. We wrote it in Suneido (comparable to a scripting language) for many of the same reasons Adobe wrote Lightroom in Lua.
Of course, the difference is that they chose an existing language, whereas I wrote Suneido. I would not have been as impressed if Adobe had chosen to write their own scripting language. Of course, that raises the question whether we should have used an existing language to write our trucking software. If I was starting today, I might say yes, but given the situation when we started (years ago) I'm not sure I'd do it any differently.
Tuesday, November 11, 2008
Another Milestone
A standard Suneido WorkSpace, right? Yes, but what you can't see is that it's a client running from the jSuneido server (which happens to be running on OS X). Pretty cool (for me, anyway!)

It actually wasn't too hard to get to this point. I had a few annoying problems with byte order since Java ByteBuffer's default to big endian, but native x86 order is little endian. In most places cSuneido was using big endian instead of native order but not everywhere, as I found out the hard way! One last gotcha was that ByteBuffer slice doesn't keep the source's byte order - easy enough to handle but somewhat counterintuitive.
As I keep reminding myself, there's still lots to do, but it's still nice to reach some tangible milestones :-)

It actually wasn't too hard to get to this point. I had a few annoying problems with byte order since Java ByteBuffer's default to big endian, but native x86 order is little endian. In most places cSuneido was using big endian instead of native order but not everywhere, as I found out the hard way! One last gotcha was that ByteBuffer slice doesn't keep the source's byte order - easy enough to handle but somewhat counterintuitive.
As I keep reminding myself, there's still lots to do, but it's still nice to reach some tangible milestones :-)
Thursday, October 30, 2008
jSuneido Progress Milestone
With most of the server functional I decided it was time to try to get a Windows cSuneido client to talk to jSuneido.
I wasn't sure the best way to do this since I'm developing on OS X on the Mac and I can't run the Windows client there. I could get Eclipse and jSuneido running on Windows on Parallels, but that seemed like a lot of redundant effort.
I wasn't sure exactly how to do it, but the simplest seemed to be to get the Windows client running on Parallels connecting to the Java server on OS X. This turned out to be easy - although they're both on the same physical computer Windows and OS X had different IP addresses so it was easy to connect.
After stubbing out a couple more of the client-server commands I got to "nonexistent table: stdlib". I added code to create stdlib and got "can't find Init" (Init is the first thing Suneido tries to run.) I added code to output an Init to stdlib that just called Exit(). Sure enough, the client starts successfully, loads Init from the server, executes it, and exits normally.
This might not sound like much, but it's actually a big milestone. It means a lot of stuff is working. The next step is to implement "load" so I can dump stdlib from an existing database and load it into a jSuneido database. In theory then I should be able to run the IDE on the Windows client from the jSuneido server.
I wasn't sure the best way to do this since I'm developing on OS X on the Mac and I can't run the Windows client there. I could get Eclipse and jSuneido running on Windows on Parallels, but that seemed like a lot of redundant effort.
I wasn't sure exactly how to do it, but the simplest seemed to be to get the Windows client running on Parallels connecting to the Java server on OS X. This turned out to be easy - although they're both on the same physical computer Windows and OS X had different IP addresses so it was easy to connect.
After stubbing out a couple more of the client-server commands I got to "nonexistent table: stdlib". I added code to create stdlib and got "can't find Init" (Init is the first thing Suneido tries to run.) I added code to output an Init to stdlib that just called Exit(). Sure enough, the client starts successfully, loads Init from the server, executes it, and exits normally.
This might not sound like much, but it's actually a big milestone. It means a lot of stuff is working. The next step is to implement "load" so I can dump stdlib from an existing database and load it into a jSuneido database. In theory then I should be able to run the IDE on the Windows client from the jSuneido server.
Wednesday, October 22, 2008
Back to jSuneido
Yesterday I sat down to get back to work on jSuneido after almost two months of inactivity. It was a struggle. Getting over a cold might have something to do with that. I thought it might be hard to figure out where to start, but that turned out to be relatively easy. It was harder to remember how everything (in my code) works - how to do what I wanted to do. Thankfully, what I started with was fairly straightforward.
The harder part turned out to be getting my head back into it. Sitting at a desk, focusing on a single task is quite a change from traveling, where you are constantly jumping around. And it's going to be hard to regain the momentum and drive I had at first. Even before I left, that was getting harder. Oh well, if it was easy, anyone could do it.
On the positive side, I managed to fight off most of my urges to get distracted and I did write a good chunk of code and make a fair bit of progress. That's a lot more motivating than thrashing around and producing nothing!
As I mentioned before, I think I'm getting quite close to having a mostly functional single threaded server. That leaves the big challenges of implementing the Suneido language (needed even in the server for triggers and rules) and the multi-threading, of course.
On another positive note, I still feel pretty confident that this is a "good" direction to go. Only time will tell for sure, but I haven't encountered anything (yet) that would make me think I've taken a wrong turn. One person on the Suneido forum did express concern that a Java version would lose some of the ease of install and lack of dependencies that the current version has, but I think those concerns can be addressed.
The harder part turned out to be getting my head back into it. Sitting at a desk, focusing on a single task is quite a change from traveling, where you are constantly jumping around. And it's going to be hard to regain the momentum and drive I had at first. Even before I left, that was getting harder. Oh well, if it was easy, anyone could do it.
On the positive side, I managed to fight off most of my urges to get distracted and I did write a good chunk of code and make a fair bit of progress. That's a lot more motivating than thrashing around and producing nothing!
As I mentioned before, I think I'm getting quite close to having a mostly functional single threaded server. That leaves the big challenges of implementing the Suneido language (needed even in the server for triggers and rules) and the multi-threading, of course.
On another positive note, I still feel pretty confident that this is a "good" direction to go. Only time will tell for sure, but I haven't encountered anything (yet) that would make me think I've taken a wrong turn. One person on the Suneido forum did express concern that a Java version would lose some of the ease of install and lack of dependencies that the current version has, but I think those concerns can be addressed.
Sunday, October 19, 2008
Rescued from Eclipse by Time Machine
In preparation for getting back to work on jSuneido I thought I would get the recent updates. I go to Help > Software Updates and click on Update, I get:
I try again, but this time I do select, just Eclipse Platform and Eclipse Java Development Tools. That runs for a while, and I say ok to restarting. So far, so good. I go back into the updates, don't select anything (which seems to be the same as selecting everything), and get similar errors. I uncheck the first item in the list, Antler IDE and the errors go away. I tell it to go ahead, it runs for a while, and I say ok to restarting. But instead of restarting I get:
At that point I happen to notice the Time Machine (OS X's automatic backup system) icon spinning in the menu bar. A light comes on. I should be able to restore to before my problems using Time Machine! Sure enough, a few minutes later I'm back to before things got messed up. (I was a little disappointed that it restored the entire folder, rather than just what had changed. It's smarter when it's backing up. But I guess you don't restore that often, and it didn't take too long.)
I re-did the Platform and JDT updates and left the rest. I think I'll just ignore them for the time being and try to get some real work done. These frequent "automated" updates are great ... until they don't work.
The software items you selected may not be valid with your current installation. Do you want to open the wizard anyway to review the selections?I didn't select anything so I'm not sure what it's referring to. I click on Yes. There are some errors related to "equinox". A quick web search indicates that's the Eclipse runtime. That sounds pretty basic, why would it have errors?
I try again, but this time I do select, just Eclipse Platform and Eclipse Java Development Tools. That runs for a while, and I say ok to restarting. So far, so good. I go back into the updates, don't select anything (which seems to be the same as selecting everything), and get similar errors. I uncheck the first item in the list, Antler IDE and the errors go away. I tell it to go ahead, it runs for a while, and I say ok to restarting. But instead of restarting I get:
Eclipse executable launcher was unable to locate its companion shared libraryA Google search doesn't find anything that sounds like my problem or helps much. Now what? Reinstall Eclipse? I start on that path and download the latest, but then I realize I'll have to reinstall all my plugins. Yuck.
At that point I happen to notice the Time Machine (OS X's automatic backup system) icon spinning in the menu bar. A light comes on. I should be able to restore to before my problems using Time Machine! Sure enough, a few minutes later I'm back to before things got messed up. (I was a little disappointed that it restored the entire folder, rather than just what had changed. It's smarter when it's backing up. But I guess you don't restore that often, and it didn't take too long.)
I re-did the Platform and JDT updates and left the rest. I think I'll just ignore them for the time being and try to get some real work done. These frequent "automated" updates are great ... until they don't work.
Wednesday, October 15, 2008
Speaking of Slick
 This is me on the (glass) stairs in the Apple store in Sydney, Australia. I've been in some smaller Apple stores but they weren't anywhere near as impressive as the three glass and chrome floors of this one. They had (literally) hundreds of Mac's, iPods, and iPhones out for people to touch and try.
This is me on the (glass) stairs in the Apple store in Sydney, Australia. I've been in some smaller Apple stores but they weren't anywhere near as impressive as the three glass and chrome floors of this one. They had (literally) hundreds of Mac's, iPods, and iPhones out for people to touch and try.
Apple MacBook Lust
Rationally, I know it's just slick marketing, but even so, after watching the promo video, I can't help lust after a new MacBook. What geek could resist?
Friday, August 22, 2008
Microsoft Patents Page Up/Down
http://radar.oreilly.com/2008/08/annals-of-the-patently-absurd-1.html
Some times it seems amazing that we ever actually accomplish anything amid so much nonsense.
Some times it seems amazing that we ever actually accomplish anything amid so much nonsense.
Monday, August 18, 2008
Friday, August 15, 2008
Rich Gmail
Gmail doesn't let you do much in the way of "rich" formatted emails.
One way around this is to write your email in Google Documents and then copy and paste into Gmail.
This lets you, for example, insert images. And since you can edit the HTML from Google Docs you can tweak it even more.
The copy and paste isn't perfect, but it works fairly well.
One way around this is to write your email in Google Documents and then copy and paste into Gmail.
This lets you, for example, insert images. And since you can edit the HTML from Google Docs you can tweak it even more.
The copy and paste isn't perfect, but it works fairly well.
Saturday, August 09, 2008
Managing Customer Service
I took my Prius in for an oil change the other day. When I went to pick it up the person on the counter was on the phone. No problem, must be talking to a customer. But as I stood at the counter waiting, it became obvious it was a personal call making plans for the weekend. I kept expecting to hear, "I'll call you back, I've got a customer", but no, I stood and listened while the conversation continued for several more minutes until they settled their plans.
I got a little annoyed, but it was only a few minutes, no big deal.
What I was thinking about was that if it was my dealership, I really wouldn't want to treat customers like that. But how do you prevent, or at least minimize, that kind of thing? Your first thought might be to ban personal calls. But that won't get you good customer service. That'll get you unhappy staff and higher turnover. And personal calls aren't the only cause of poor customer service.
Although the customer support people at my company don't deal face to face, I still worry about it. There are still lots of ways to treat someone poorly over the phone.
One of the ways I try to combat it is to tell stories about good and bad customer service in our support meetings. Of course, most people think they give good service and they would never be rude to someone like that. But I hope that it helps raise their awareness and helps them think about it from the customer's perspective.
At the same time, I do put some of the "blame" on the individual. After all, even if this was a non-work situation, it's still pretty rude to ignore someone standing in front of you and gab on the phone. Although, with cell phones this is becoming increasingly common, which may be part of the problem.
There's a lot of hype about how the younger generation is so much better at multi-tasking. I don't buy it, it appears more to me that the skill at play is in not paying attention. The research isn't conclusive but there are certainly results that show that multi-tasking doesn't work, in the sense that you just end up doing a half-assed job of each task. Luckily (or sadly, depending on your perspective) that doesn't matter because most of the things being multi-tasked aren't of any value anyway.
On the other hand, I'm starting to sound a lot like my parents :-( "Kid's these days - no respect!"
I got a little annoyed, but it was only a few minutes, no big deal.
What I was thinking about was that if it was my dealership, I really wouldn't want to treat customers like that. But how do you prevent, or at least minimize, that kind of thing? Your first thought might be to ban personal calls. But that won't get you good customer service. That'll get you unhappy staff and higher turnover. And personal calls aren't the only cause of poor customer service.
Although the customer support people at my company don't deal face to face, I still worry about it. There are still lots of ways to treat someone poorly over the phone.
One of the ways I try to combat it is to tell stories about good and bad customer service in our support meetings. Of course, most people think they give good service and they would never be rude to someone like that. But I hope that it helps raise their awareness and helps them think about it from the customer's perspective.
At the same time, I do put some of the "blame" on the individual. After all, even if this was a non-work situation, it's still pretty rude to ignore someone standing in front of you and gab on the phone. Although, with cell phones this is becoming increasingly common, which may be part of the problem.
There's a lot of hype about how the younger generation is so much better at multi-tasking. I don't buy it, it appears more to me that the skill at play is in not paying attention. The research isn't conclusive but there are certainly results that show that multi-tasking doesn't work, in the sense that you just end up doing a half-assed job of each task. Luckily (or sadly, depending on your perspective) that doesn't matter because most of the things being multi-tasked aren't of any value anyway.
On the other hand, I'm starting to sound a lot like my parents :-( "Kid's these days - no respect!"
Wednesday, July 30, 2008
Programmers Need Supervision
I was using Windows on my Mac for the first time in a while. The first frustration is that when you haven't used Windows for a while it wants to download and install massive updates, in my case include Vista Service Pack 1. Not everyone leaves their machine running all the time! And when you start it up to do some actual task, the last thing you want to do is wait for updates to install.
Next I tried to open a PDF help file and Adobe Reader wanted to update itself. Except the update failed saying I didn't haven't sufficient permissions, even though I was logged in as Administrator. That wouldn't have been so bad except the failed install left me without a working Reader, neither old nor new.
So I downloaded the latest Adobe Reader 9 and installed that (after rebooting in hopes of cleaning up whatever mess the last install might have left)
This install succeeded (I guess I did have sufficient permissions after all!) But the process was somewhat amusing. For example one of the stages was "Creating Duplicate Files". That seems like a strange thing to do, let alone advertise. Most of the messages it displayed looked more like debugging than anything else. Do I really need to see every registry key it's creating? Even if I did want to see, it flashes by too fast to read anyway. Write it to a log file if you really feel someone might want to look at it.
Then it sat on 99.90 percent complete for a long time. That's typical, but the funny part is that it wasn't 99% done or even 99.9% done, it was 99.90% done. Even more amusing because that 0.10% took about 10% of the install time. Why even display a number? It's such a rough estimate that the progress bar is more than sufficient.
And this is from Adobe who probably have some huge number of people who architect, design, review, and test this stuff. How come none of them questioned all this debugging output?
Someone really needs to supervise us programmers!
Next I tried to open a PDF help file and Adobe Reader wanted to update itself. Except the update failed saying I didn't haven't sufficient permissions, even though I was logged in as Administrator. That wouldn't have been so bad except the failed install left me without a working Reader, neither old nor new.
So I downloaded the latest Adobe Reader 9 and installed that (after rebooting in hopes of cleaning up whatever mess the last install might have left)
This install succeeded (I guess I did have sufficient permissions after all!) But the process was somewhat amusing. For example one of the stages was "Creating Duplicate Files". That seems like a strange thing to do, let alone advertise. Most of the messages it displayed looked more like debugging than anything else. Do I really need to see every registry key it's creating? Even if I did want to see, it flashes by too fast to read anyway. Write it to a log file if you really feel someone might want to look at it.
Then it sat on 99.90 percent complete for a long time. That's typical, but the funny part is that it wasn't 99% done or even 99.9% done, it was 99.90% done. Even more amusing because that 0.10% took about 10% of the install time. Why even display a number? It's such a rough estimate that the progress bar is more than sufficient.
And this is from Adobe who probably have some huge number of people who architect, design, review, and test this stuff. How come none of them questioned all this debugging output?
Someone really needs to supervise us programmers!
Mac TV and iTunes movie rentals
After I got my new iMac I decided to try using my old Mac Mini as my DVR & DVD player.
I bought an Elgato eyetv 250 cable tuner/converter. The tuner/converter works well, but the remote that came it seems cheap and isn't very reliable. You have to hit the buttons multiple times and point it exactly right, even though I'm only about 6 feet from the TV. And many of the buttons on the remote are either labelled very cryptically, or not labelled at all. (just colored!)
One of the reasons I've resisted digital cable and set-top boxes is that you end up (in most cases) with a single "tuner" and the only way to change channels is through the box. With my old fashioned analog cable I have a tuner in the tv and one in the eyetv so I can record one channel and watch another. And since eyetv has it's own tuner it can change channels to record the right one. (Much more difficult with a separate set-top box.)
I'd heard good things about Elgato's eyetv software. I can't say I was too impressed. It works, but the user interface is the usual confusing maze. But I haven't used any other software so it could still be better than the others.
Although the form factor of the Mac Mini is ideal for this, it soon becomes obvious that it isn't what the system is designed for. I don't want update notices popping up in the middle of a movie. And although you can do just about everything without a keyboard, you tend to get pop up warnings about no keyboard connected. And although a wireless mouse and keyboard are pretty much essential, the battery life sucks. So your movie also gets interupted by low battery warnings!
I wanted to use the new tiny wireless aluminum keyboard, but it was quite a struggle to get it to work with the mini. Eventually I got it connected.
Meanwhile, Shelley has yet to try using this setup. I don't blame her - booting up the Mac, getting into the software, etc. is not trivial. At least she can still use the tv as usual.
There are other advantages to having an internet connected tv. It's nice to be able to watch videos from the internet on tv instead of sitting at my computer. And I have access to my music and photo library. Although, I don't have it connected to my stereo so the sound quality is crappy. But if I connect it to the stereo then I'd have to turn that on to watch tv.
Another motivation for all this was iTunes movie rentals. I was excited about this when it was announced, but then it was US only and it was slow coming to Canada. Recently I went to check and found it had come to Canada back in June. Strange they didn't make a bigger deal out of it - I hadn't heard anything and I was looking for it.
My first experience with iTunes movie rentals was pretty much perfect. I went into iTunes, picked a movie, clicked Rent, and started watching. iTunes already has my credit card into so it was a painless process. The quality was great, indistinguishable from a DVD (on my ancient tv), and there were no pauses, lags, or choppiness. The price is about the same as local video rental ($3.99 or $4.99) but I don't have to pick it up or return it. I was sold.
Unfortunately, my second experience was not so good. For whatever reason, the download rate was incredibly slow. And since the download was slower than watching speed it was impossible to watch and download concurrently. It still worked and I watched the movie the next night, but the instant gratification was gone.
I'll try again and see which experience is typical. The nice part is that I don't have to sign up or make any commitment, I can just use it when/if I feel like it.
Although Mac Mini's are relatively cheap, it's still an expensive DVR/DVD player. It's definitely a place for a special purpose device. The Apple TV box is close, but it has no DVD player and it has no facility to connect to regular TV. I'm sure these were deliberate choices, but it means you still need other devices as well. I want a single device.
I have mixed feelings. It's definitely not the ideal setup, and it pretty much requires a geek to operate. But at the same time I've become hooked on some of the features it provides.
I bought an Elgato eyetv 250 cable tuner/converter. The tuner/converter works well, but the remote that came it seems cheap and isn't very reliable. You have to hit the buttons multiple times and point it exactly right, even though I'm only about 6 feet from the TV. And many of the buttons on the remote are either labelled very cryptically, or not labelled at all. (just colored!)
One of the reasons I've resisted digital cable and set-top boxes is that you end up (in most cases) with a single "tuner" and the only way to change channels is through the box. With my old fashioned analog cable I have a tuner in the tv and one in the eyetv so I can record one channel and watch another. And since eyetv has it's own tuner it can change channels to record the right one. (Much more difficult with a separate set-top box.)
I'd heard good things about Elgato's eyetv software. I can't say I was too impressed. It works, but the user interface is the usual confusing maze. But I haven't used any other software so it could still be better than the others.
Although the form factor of the Mac Mini is ideal for this, it soon becomes obvious that it isn't what the system is designed for. I don't want update notices popping up in the middle of a movie. And although you can do just about everything without a keyboard, you tend to get pop up warnings about no keyboard connected. And although a wireless mouse and keyboard are pretty much essential, the battery life sucks. So your movie also gets interupted by low battery warnings!
I wanted to use the new tiny wireless aluminum keyboard, but it was quite a struggle to get it to work with the mini. Eventually I got it connected.
Meanwhile, Shelley has yet to try using this setup. I don't blame her - booting up the Mac, getting into the software, etc. is not trivial. At least she can still use the tv as usual.
There are other advantages to having an internet connected tv. It's nice to be able to watch videos from the internet on tv instead of sitting at my computer. And I have access to my music and photo library. Although, I don't have it connected to my stereo so the sound quality is crappy. But if I connect it to the stereo then I'd have to turn that on to watch tv.
Another motivation for all this was iTunes movie rentals. I was excited about this when it was announced, but then it was US only and it was slow coming to Canada. Recently I went to check and found it had come to Canada back in June. Strange they didn't make a bigger deal out of it - I hadn't heard anything and I was looking for it.
My first experience with iTunes movie rentals was pretty much perfect. I went into iTunes, picked a movie, clicked Rent, and started watching. iTunes already has my credit card into so it was a painless process. The quality was great, indistinguishable from a DVD (on my ancient tv), and there were no pauses, lags, or choppiness. The price is about the same as local video rental ($3.99 or $4.99) but I don't have to pick it up or return it. I was sold.
Unfortunately, my second experience was not so good. For whatever reason, the download rate was incredibly slow. And since the download was slower than watching speed it was impossible to watch and download concurrently. It still worked and I watched the movie the next night, but the instant gratification was gone.
I'll try again and see which experience is typical. The nice part is that I don't have to sign up or make any commitment, I can just use it when/if I feel like it.
Although Mac Mini's are relatively cheap, it's still an expensive DVR/DVD player. It's definitely a place for a special purpose device. The Apple TV box is close, but it has no DVD player and it has no facility to connect to regular TV. I'm sure these were deliberate choices, but it means you still need other devices as well. I want a single device.
I have mixed feelings. It's definitely not the ideal setup, and it pretty much requires a geek to operate. But at the same time I've become hooked on some of the features it provides.
Labels:
mac
Tuesday, July 29, 2008
jSuneido Progress
I have to admit my sense of urgency for this project is fading a little bit. Don't get me wrong, I'm still committed to it and working steadily on it. But it's just a little too big to push through to completion on that initial excitement.
On the positive side, I pretty much have the database query optimization working. That's a big step forward since it's one of the most complex parts of Suneido. It's gone better than I expected. But I think my expectations are a little more negative than they should be, given that I'm just porting working code.
As I suspected might happen, I've found a few bugs in the existing C++ code. A few times I thought I'd found major bugs but it turned out I was just not understanding how it was working. The few real bugs I've found haven't been very serious, which makes sense given that the current version has been pretty heavily tested and used in production.
The next step is query execution. This is a lot simpler than the optimization and should go fairly quickly. It'll be interesting to run some benchmarks and see how performance compares.
What's left after that? I have to hook up the server to the database and do the crash recovery - that should just about complete the database server part. Wrong - I still have to do the multi-threading - ouch. Then comes the fun part of implementing the language. This is only needed in the database server for rules and triggers - the bulk of what the database server does doesn't need the language at all.
It would be nice to get the bulk of this done before I go on holidays for a month in September. Not that I'd want to deploy it just before going on holidays, but the more complete it is, the less I'll have to try to remember where I was at when I get back.
Of course, the next obvious project is to port the client side. The big challenge here is the user interface. This is much less well defined and intertwined with Windows so it will be a much messier job. But also in some ways more rewarding since UI is a lot more visible than the behind the scenes server. So I won't have any shortage of challenges for the foreseeable future!
On the positive side, I pretty much have the database query optimization working. That's a big step forward since it's one of the most complex parts of Suneido. It's gone better than I expected. But I think my expectations are a little more negative than they should be, given that I'm just porting working code.
As I suspected might happen, I've found a few bugs in the existing C++ code. A few times I thought I'd found major bugs but it turned out I was just not understanding how it was working. The few real bugs I've found haven't been very serious, which makes sense given that the current version has been pretty heavily tested and used in production.
The next step is query execution. This is a lot simpler than the optimization and should go fairly quickly. It'll be interesting to run some benchmarks and see how performance compares.
What's left after that? I have to hook up the server to the database and do the crash recovery - that should just about complete the database server part. Wrong - I still have to do the multi-threading - ouch. Then comes the fun part of implementing the language. This is only needed in the database server for rules and triggers - the bulk of what the database server does doesn't need the language at all.
It would be nice to get the bulk of this done before I go on holidays for a month in September. Not that I'd want to deploy it just before going on holidays, but the more complete it is, the less I'll have to try to remember where I was at when I get back.
Of course, the next obvious project is to port the client side. The big challenge here is the user interface. This is much less well defined and intertwined with Windows so it will be a much messier job. But also in some ways more rewarding since UI is a lot more visible than the behind the scenes server. So I won't have any shortage of challenges for the foreseeable future!
Tuesday, July 22, 2008
Inline PDF for Mac Firefox 3
One of my last annoyances with Firefox on the Mac was that it didn't display PDF's "inline" - in the browser window. Instead, you had to download and open it in another program.
It wasn't just Firefox either, originally Safari had issues with this as well.
It always seemed odd to me because OS X is otherwise very PDF "friendly".
It bugged me again today so I searched to see if there was a solution yet and I found the firefox-mac-pdf plugin.
Of course, the first time I tried it I got a blank screen :-( but the next one I tried worked. The one that wouldn't work is landscape - maybe that's the problem, although I couldn't see any known problems with landscape.
Strangely, Gmail still forces you to download PDF's to view them. (I think by setting the Content-Disposition header.) I'm not sure why they do this. Maybe because otherwise people can't figure out how to download because they don't think to right-click and save. You could always have separate download and view links, but that only makes sense if you know the browser can handle viewing, which is probably difficult to determine.
Still, it's nice to finally have this.
It wasn't just Firefox either, originally Safari had issues with this as well.
It always seemed odd to me because OS X is otherwise very PDF "friendly".
It bugged me again today so I searched to see if there was a solution yet and I found the firefox-mac-pdf plugin.
Of course, the first time I tried it I got a blank screen :-( but the next one I tried worked. The one that wouldn't work is landscape - maybe that's the problem, although I couldn't see any known problems with landscape.
Strangely, Gmail still forces you to download PDF's to view them. (I think by setting the Content-Disposition header.) I'm not sure why they do this. Maybe because otherwise people can't figure out how to download because they don't think to right-click and save. You could always have separate download and view links, but that only makes sense if you know the browser can handle viewing, which is probably difficult to determine.
Still, it's nice to finally have this.
Wednesday, July 16, 2008
jSuneido - progress and Antlr
I now have the main database query language parsing to syntax trees (using Antlr). This is a good step because it includes all the expression syntax. Next, I'll work on the query optimization, and then query execution.
Antlr is working pretty well. One thing I don't like (but it's not unique to Antlr) is that the grammar gets obscured by the "actions". It's too bad, because a big reason for using something like Antlr is so the grammar is more explicit and easier to read and modify.
For example:
cols : ID (','? ID )* ;
turns into:
cols returns [List list]
@init { list = new ArrayList(); }
: i=ID { list.add($i.text); }
(','? j=ID { list.add($j.text); }
)* ;
(There may be easier/better ways of doing some of what I'm doing, but I think the issue would still remain.)
It would be nice if you could somehow separate the actions from the grammar, similar to how CSS separates style from HTML.
This might also solve another issue with Antlr. To write a tree grammar to process your syntax tree you copy your grammar and then modify it. Sounds like a maintenance problem to me.
Similarly, Suneido's language has pretty much the same expression grammar as the database query language. But I'm going to have to copy and modify because the actions will be different. (For queries I build a syntax tree, but for the language I generate byte code on the fly.) Which means if I want to change or add something, I have to do it in multiple places. Granted, that's no different than the handwritten C++ parsing code, but you'd like a better solution from a sophisticated tool.
Antlr is working pretty well. One thing I don't like (but it's not unique to Antlr) is that the grammar gets obscured by the "actions". It's too bad, because a big reason for using something like Antlr is so the grammar is more explicit and easier to read and modify.
For example:
cols : ID (','? ID )* ;
turns into:
cols returns [List
@init { list = new ArrayList
(','? j=ID { list.add($j.text); }
)* ;
(There may be easier/better ways of doing some of what I'm doing, but I think the issue would still remain.)
It would be nice if you could somehow separate the actions from the grammar, similar to how CSS separates style from HTML.
This might also solve another issue with Antlr. To write a tree grammar to process your syntax tree you copy your grammar and then modify it. Sounds like a maintenance problem to me.
Similarly, Suneido's language has pretty much the same expression grammar as the database query language. But I'm going to have to copy and modify because the actions will be different. (For queries I build a syntax tree, but for the language I generate byte code on the fly.) Which means if I want to change or add something, I have to do it in multiple places. Granted, that's no different than the handwritten C++ parsing code, but you'd like a better solution from a sophisticated tool.
Tuesday, July 15, 2008
Mylyn - task management Eclipse plugin
I just watched an interesting talk on the Mylyn plugin for Eclipse.
It looks great, which is funny because before now I didn't really know what it was, so I've been doing my best to hide/close/disable all the Mylyn stuff in Eclipse. I'll have to look at starting to use it.
As usual, when I see these great tools, I want to add them to Suneido. If only there were more hours in the day!
It looks great, which is funny because before now I didn't really know what it was, so I've been doing my best to hide/close/disable all the Mylyn stuff in Eclipse. I'll have to look at starting to use it.
As usual, when I see these great tools, I want to add them to Suneido. If only there were more hours in the day!
Labels:
eclipse
Friday, July 11, 2008
jSuneido - progress and premonitions
For "fun", I decided to hook up the database request parsing and execution to the server code. It was pretty easy. I could then telnet into the server and create/modify/delete tables in the database. Can't actually do anything with the resulting tables, but still a good milestone.
On a big project, it's great when you can hook up some pieces and have them actually do something. Most of the time you're down in the bowels of the code plugging away at little pieces of functionality. It's nice to get reminded that the whole system is actually going to do something!
I've made good progress in the last week or two. I've been averaging about 200 lines of code per day. Unfortunately, it's getting hard to measure that because the lines of code are exaggerated by things like the generated parsing and lexing code. The metrics tool I'm using doesn't seem to allow excluding some files.
However, in all this progress estimation I've been glossing over one big stumbling block - concurrency. A port of the existing implementation will not be particularly useful. I still have to make it run multi-threaded - arguably a tougher nut to crack.
I just finished "reading" The Art of Multiprocessor Programming. (I'm not sure "Art" belongs in the title of a book full of lemmas and proofs!) It's pretty dense but I found it fascinating. I haven't encountered so many novel algorithms in a long time. Of course, it only reinforced the fact that concurrency is hard, and often counter-intuitive. The chapter on Transactional Memory was really interesting. This sounds like the direction for the future. (check out a podcast from OSCON and a paper from OOPSLA)
The issue of making Suneido multi-threaded has been in the back of my mind throughout this project. Every so often I spend some time thinking about it.
Although it would be possible to just add some naive coarse grained locking to the existing code, that's not going to give good results. I'm pretty much resigned to having to do some redesign to accommodate concurrency.
Yesterday I came up with an idea for using copy-on-write for index nodes. The more I thought about it, the better I liked it. Last night I was lying in bed thinking about it. (I know, what a geek, I can't help it.) It just seemed a little too good to be true. Sure enough, I had been overlooking some critical issues. Luckily (?) I stayed awake long enough to think of another alternative. It was a good example of how concurrency (or any complex system) is hard to reason about correctly with our (mine, anyway) limited brainpower.
PS. In case it wasn't obvious, the "premonition" part of the title refers to the concurrency issue. The definition seems appropriate: "A warning of an impending event, experienced as foreboding, anxiety and intuitive sense of dread." Although I'm not crazy about the rest of the definition: "Premonitions tend to occur before disaster"!
On a big project, it's great when you can hook up some pieces and have them actually do something. Most of the time you're down in the bowels of the code plugging away at little pieces of functionality. It's nice to get reminded that the whole system is actually going to do something!
I've made good progress in the last week or two. I've been averaging about 200 lines of code per day. Unfortunately, it's getting hard to measure that because the lines of code are exaggerated by things like the generated parsing and lexing code. The metrics tool I'm using doesn't seem to allow excluding some files.
However, in all this progress estimation I've been glossing over one big stumbling block - concurrency. A port of the existing implementation will not be particularly useful. I still have to make it run multi-threaded - arguably a tougher nut to crack.
I just finished "reading" The Art of Multiprocessor Programming. (I'm not sure "Art" belongs in the title of a book full of lemmas and proofs!) It's pretty dense but I found it fascinating. I haven't encountered so many novel algorithms in a long time. Of course, it only reinforced the fact that concurrency is hard, and often counter-intuitive. The chapter on Transactional Memory was really interesting. This sounds like the direction for the future. (check out a podcast from OSCON and a paper from OOPSLA)
The issue of making Suneido multi-threaded has been in the back of my mind throughout this project. Every so often I spend some time thinking about it.
Although it would be possible to just add some naive coarse grained locking to the existing code, that's not going to give good results. I'm pretty much resigned to having to do some redesign to accommodate concurrency.
Yesterday I came up with an idea for using copy-on-write for index nodes. The more I thought about it, the better I liked it. Last night I was lying in bed thinking about it. (I know, what a geek, I can't help it.) It just seemed a little too good to be true. Sure enough, I had been overlooking some critical issues. Luckily (?) I stayed awake long enough to think of another alternative. It was a good example of how concurrency (or any complex system) is hard to reason about correctly with our (mine, anyway) limited brainpower.
PS. In case it wasn't obvious, the "premonition" part of the title refers to the concurrency issue. The definition seems appropriate: "A warning of an impending event, experienced as foreboding, anxiety and intuitive sense of dread." Although I'm not crazy about the rest of the definition: "Premonitions tend to occur before disaster"!
Thursday, July 10, 2008
Antlr Frustrations
I just spent a frustrating morning fighting to get Suneido's query grammar to work with Antlr.
I kept getting "no viable alternative" and "no start rule (no rule can obviously be followed by EOF)"
I searched on the web but didn't find any answers.
I made more or less random changes to my grammar and if I cut out the more complex stuff it would work but that wasn't much help.
I started trying small examples, like:
expr : m (('+'|'-') m)* ;
m : ID
| '(' expr ')' ;
ID : ('a'..'z')+ ;
WS : (' '|'\t'|'\r'|'\n')+ {skip();} ;
which is pretty much straight out of the book but exhibited the same problems.
I started to wonder if something was messed up in my copy of Antlr or something.
Eventually, I found a post that explained it. The problem is that Antlr identifies "start" rules (ones that can end with EOF) by looking for rules that are not used anywhere else in the grammar. When you have recursion on the "start" rule (expr in this case), it doesn't work. The above example could be fixed by adding:
prog : expr ;
It makes sense once you know the problem, but it certainly wasn't obvious at first. And I don't recall the book mentioning it anywhere. It seems like an obvious "gotcha". I can't be the only person to get caught by this. It would have been nice if the error message said something like "make sure your start rule is not used in another rule".
Or else just make it work. Obviously, the rule you start with should be endable by EOF, whether or not it's used elsewhere. That's probably a little tricky to handle, but compared to the complexity of Antlr it's nothing.
This kind of frustration is one of the downsides of using someone else's tools and libraries.
Various other stupid mistakes on my part added to the frustration, but eventually I got things starting to work.
I kept getting "no viable alternative" and "no start rule (no rule can obviously be followed by EOF)"
I searched on the web but didn't find any answers.
I made more or less random changes to my grammar and if I cut out the more complex stuff it would work but that wasn't much help.
I started trying small examples, like:
expr : m (('+'|'-') m)* ;
m : ID
| '(' expr ')' ;
ID : ('a'..'z')+ ;
WS : (' '|'\t'|'\r'|'\n')+ {skip();} ;
which is pretty much straight out of the book but exhibited the same problems.
I started to wonder if something was messed up in my copy of Antlr or something.
Eventually, I found a post that explained it. The problem is that Antlr identifies "start" rules (ones that can end with EOF) by looking for rules that are not used anywhere else in the grammar. When you have recursion on the "start" rule (expr in this case), it doesn't work. The above example could be fixed by adding:
prog : expr ;
It makes sense once you know the problem, but it certainly wasn't obvious at first. And I don't recall the book mentioning it anywhere. It seems like an obvious "gotcha". I can't be the only person to get caught by this. It would have been nice if the error message said something like "make sure your start rule is not used in another rule".
Or else just make it work. Obviously, the rule you start with should be endable by EOF, whether or not it's used elsewhere. That's probably a little tricky to handle, but compared to the complexity of Antlr it's nothing.
This kind of frustration is one of the downsides of using someone else's tools and libraries.
Various other stupid mistakes on my part added to the frustration, but eventually I got things starting to work.
Inside Lightroom
Lightroom is Adobe's digital photography software. I really like it. (And I don't "really like" much software!) It competes with Apple's Aperture, which I haven't tried. (but I'm getting tempted to get a copy to check it out)
Lately I've listened to a few podcasts from/with the Lightroom developers. Being in the software development business I find it fascinating to get a peek inside other development, especially for a product that is innovative like Lightroom. The podcast feed is at:
http://rss.adobe.com/www/special/light_room.rss
Or: http://www.mulita.com/blog/?cat=3
For another view, check out this video interview with Phil Clevenger, the main Lightroom UI designer.
Lately I've listened to a few podcasts from/with the Lightroom developers. Being in the software development business I find it fascinating to get a peek inside other development, especially for a product that is innovative like Lightroom. The podcast feed is at:
http://rss.adobe.com/www/special/light_room.rss
Or: http://www.mulita.com/blog/?cat=3
For another view, check out this video interview with Phil Clevenger, the main Lightroom UI designer.
Wednesday, July 09, 2008
HMAC SHA1, Amazon SQS, and My First C# Program
We're looking at using Amazon SQS (Simple Queue Service) for a project. One end of the queue will be a Ruby on Rails application, the other end will be our Suneido application. There is code we can use from Ruby, but not from Suneido. (The new Programming Amazon Web Services is quite helpful.)
As with S3, the issue is the authentication. Amazon web services use HMAC-SHA1. For S3 we ended up using a separate external command line program, but we couldn't find anything similar for SQS.
I looked at adding SHA1 to Suneido (it already has MD5) but using the Win32 crypto api's is very confusing.
We found a command line sha1sum and figured we could use it. In my ignorance I didn't realize the difference between straight SHA1 and HMAC-SHA1. So much for using sha1sum.
Writing (or using) something in Java was another possibility, especially since I'm in the middle of Java right now, but then we'd have to worry about whether or not our clients have the Java runtime, and which version.
With our clients, on Windows, .Net is a safer bet. I looked at Amazon's C# sample code and the HMAC-SHA1 part looked pretty simple - .Net has an HMACSHA1 class that makes it pretty easy.
So I downloaded the free Microsoft Visual C# 2008 Express and wrote my very first C# program. The source is only 25 lines long and I copied most of it from other sources. (I had some problems with installing Visual C# - it took forever and I had to restart the install several times. Not sure what was going on.)
One thing that impressed me was the size of the resulting exe - 4.5 kb! Of course, it's using the .Net framework, which is huge, but as long as our clients already have that, I don't really care. In the old days, you could write tiny programs like that, but bloated exe's have become pretty much standard.
As with S3, the issue is the authentication. Amazon web services use HMAC-SHA1. For S3 we ended up using a separate external command line program, but we couldn't find anything similar for SQS.
I looked at adding SHA1 to Suneido (it already has MD5) but using the Win32 crypto api's is very confusing.
We found a command line sha1sum and figured we could use it. In my ignorance I didn't realize the difference between straight SHA1 and HMAC-SHA1. So much for using sha1sum.
Writing (or using) something in Java was another possibility, especially since I'm in the middle of Java right now, but then we'd have to worry about whether or not our clients have the Java runtime, and which version.
With our clients, on Windows, .Net is a safer bet. I looked at Amazon's C# sample code and the HMAC-SHA1 part looked pretty simple - .Net has an HMACSHA1 class that makes it pretty easy.
So I downloaded the free Microsoft Visual C# 2008 Express and wrote my very first C# program. The source is only 25 lines long and I copied most of it from other sources. (I had some problems with installing Visual C# - it took forever and I had to restart the install several times. Not sure what was going on.)
One thing that impressed me was the size of the resulting exe - 4.5 kb! Of course, it's using the .Net framework, which is huge, but as long as our clients already have that, I don't really care. In the old days, you could write tiny programs like that, but bloated exe's have become pretty much standard.
Tuesday, July 08, 2008
jSuneido and Antlr
I still haven't decided whether to use Antlr to replace my handwritten lexers and parsers in Suneido, but I decided to take it a little further.
I've been working on the methods to create/modify/drop database tables, so the obvious grammar to try was the database "admin requests" (the simplest of the grammars in Suneido).
I'd already written the basic grammar when I first played with Antlr so the main task was to hook up the grammar to jSuneido. For small, simple grammars it is often more of a challenge to "hook them up" than it is to write the grammar.
My first approach was to use Antlr's built-in AST (abstract syntax tree) support. That wasn't too bad. It definitely helped to have AntlrWorks to test and debug.
But then I had to do something with the AST. For big grammars, you can write another grammar to "parse" the AST, but that seemed like overkill for this. I could have just manually extracted the information from the AST but this isn't covered in the book and there's not much documentation.
Instead, I decided to not use the AST support and just accumulate the information myself. It took some experimentation to figure out how to do this. Again, it's not an approach the book really covers. In hindsight, I'm not sure if it was any easier than figuring out how to use the AST.
One of the weaknesses with the handwritten C++ parsers is that I didn't uncouple the parsing from the desired actions. It would be really nice to be able to use the same parser for other things e.g. checking syntax without generating code. What I'm hoping to do with jSuneido is to have the parser call an interface that I can have different implementations of. So even though I don't really need this for the admin request parser I decided to try out the approach.
Once I got it working in AntlrWorks the next step was to get it integrated into my Eclipse project. I had a few hiccups along the way. One was ending up with different versions of the Antlr compiler and runtime (which leads to lots of errors).
But eventually I got it working. I have a few things left to implement but there's enough working to validate the approach.
One downside is that building jSuneido has gotten more complex. Now you need the Antlr compiler and runtime. I guess I could eliminate the need for the compiler if I distributed the java files generated by the Antlr compiler.
Deploying jSuneido will now require the runtime as well. I'm not totally happy about that, considering one of Suneido's goals is ease of deployment.
For just the admin request lexing and parsing it's probably not worth it. The next step will be the actual database query language. But the real test is how well it works for the main Suneido language. If that goes well, then it's probably worth the "costs".
If you're interested, the code is in Subversion on SourceForge. e.g. Request.g
I've been working on the methods to create/modify/drop database tables, so the obvious grammar to try was the database "admin requests" (the simplest of the grammars in Suneido).
I'd already written the basic grammar when I first played with Antlr so the main task was to hook up the grammar to jSuneido. For small, simple grammars it is often more of a challenge to "hook them up" than it is to write the grammar.
My first approach was to use Antlr's built-in AST (abstract syntax tree) support. That wasn't too bad. It definitely helped to have AntlrWorks to test and debug.
But then I had to do something with the AST. For big grammars, you can write another grammar to "parse" the AST, but that seemed like overkill for this. I could have just manually extracted the information from the AST but this isn't covered in the book and there's not much documentation.
Instead, I decided to not use the AST support and just accumulate the information myself. It took some experimentation to figure out how to do this. Again, it's not an approach the book really covers. In hindsight, I'm not sure if it was any easier than figuring out how to use the AST.
One of the weaknesses with the handwritten C++ parsers is that I didn't uncouple the parsing from the desired actions. It would be really nice to be able to use the same parser for other things e.g. checking syntax without generating code. What I'm hoping to do with jSuneido is to have the parser call an interface that I can have different implementations of. So even though I don't really need this for the admin request parser I decided to try out the approach.
Once I got it working in AntlrWorks the next step was to get it integrated into my Eclipse project. I had a few hiccups along the way. One was ending up with different versions of the Antlr compiler and runtime (which leads to lots of errors).
But eventually I got it working. I have a few things left to implement but there's enough working to validate the approach.
One downside is that building jSuneido has gotten more complex. Now you need the Antlr compiler and runtime. I guess I could eliminate the need for the compiler if I distributed the java files generated by the Antlr compiler.
Deploying jSuneido will now require the runtime as well. I'm not totally happy about that, considering one of Suneido's goals is ease of deployment.
For just the admin request lexing and parsing it's probably not worth it. The next step will be the actual database query language. But the real test is how well it works for the main Suneido language. If that goes well, then it's probably worth the "costs".
If you're interested, the code is in Subversion on SourceForge. e.g. Request.g
Sunday, July 06, 2008
Firefox, FTP, and Sync
I've used Filezilla for the last few years for FTP. It's got a few quirks, but it works pretty well. And it has a Mac version (and Linux) which I need.
Recently I started using the FireFTP Firefox add on. It's only at version .99 but it seems to work fine. And of course, like most Firefox add ons, it's also cross-platform.
It's another example of the "browser as a platform" trend.
The more I do on the browser, and on multiple computers (work, home, laptop), the more I want to sync my browser "environment" - mostly cookies and passwords.
Up until recently I was using Google Browser Sync to do this. Again, it had some quirks, but it mostly worked. But Google has dropped the project. They recommend using Mozilla Weave. At first, I couldn't even download Weave (maybe they got swamped with traffic?) I now have it installed (a somewhat painful process) but it takes a long time to sync - a lot longer than Google did.
It underscores how performance is a lot about perception. If they didn't display a "working" dialog it would be less painfully obvious how long it took. Unless I'm rebooting, I don't really care how long a program takes to shut down, as long as it doesn't make me watch the process. Although browser restarts (required by updates) would be slower.
Weave is only at version 0.2 so hopefully it will improve. I'll use it a while longer and see.
Recently I started using the FireFTP Firefox add on. It's only at version .99 but it seems to work fine. And of course, like most Firefox add ons, it's also cross-platform.
It's another example of the "browser as a platform" trend.
The more I do on the browser, and on multiple computers (work, home, laptop), the more I want to sync my browser "environment" - mostly cookies and passwords.
Up until recently I was using Google Browser Sync to do this. Again, it had some quirks, but it mostly worked. But Google has dropped the project. They recommend using Mozilla Weave. At first, I couldn't even download Weave (maybe they got swamped with traffic?) I now have it installed (a somewhat painful process) but it takes a long time to sync - a lot longer than Google did.
It underscores how performance is a lot about perception. If they didn't display a "working" dialog it would be less painfully obvious how long it took. Unless I'm rebooting, I don't really care how long a program takes to shut down, as long as it doesn't make me watch the process. Although browser restarts (required by updates) would be slower.
Weave is only at version 0.2 so hopefully it will improve. I'll use it a while longer and see.
Saturday, June 28, 2008
jSuneido Progress & Estimation
I've written/ported about 4300 lines of Java code so far - roughly 100 lines per day since I started in mid May. That's average of course, some days none, some days a lot more. (And some days it's probably been negative when I threw out code!)
There's probably nothing wrong with 100 lines of code per day. If that was new code it'd be pretty good, but with porting I'd expect higher productivity. Sometimes the conversion from C++ to Java is very straightforward and quick, other times I have to do a fair bit of redesign.
Assuming the Java code will end up half the size of the C++ code, or about 30,000 lines, at the current rate I have another approximately 260 days to go, or about 8 months. (Although I still have no idea if "half the size" will be accurate. Some things are smaller or available pre-built in Java, but others, like the btree code, are pretty much the same size.)
It's a good example of how hard estimating is psychologically. Even though these numbers are quite clear, I still think "that can't be right". It seems like I'm making good progress. Yeah, there's lots left to do, but 8 months seems like such a long time. Then again, it's already been a month and a half and it feels like I just started yesterday.
This is when I start to rationalize/justify the lower (quicker) estimate that I want to hear. After all, at the start I was learning a new language and new IDE. And I had a lot of questions to figure out in terms of how I was going to handle the conversion. Once I get up to speed it should go faster, right? Well, maybe, but then again, things can slow down too, when you hit a snag or when you've got a million finishing touches to do.
Part of the problem is that it's much easier to maintain motivation and drive for a short period. Once a project extends as long as a year it's a lot tougher to keep up the momentum, and a lot easier to get distracted (like with replication!). However, the nagging issues with the current Suneido and the business drive towards larger clients will continue to provide motivation!
There's probably nothing wrong with 100 lines of code per day. If that was new code it'd be pretty good, but with porting I'd expect higher productivity. Sometimes the conversion from C++ to Java is very straightforward and quick, other times I have to do a fair bit of redesign.
Assuming the Java code will end up half the size of the C++ code, or about 30,000 lines, at the current rate I have another approximately 260 days to go, or about 8 months. (Although I still have no idea if "half the size" will be accurate. Some things are smaller or available pre-built in Java, but others, like the btree code, are pretty much the same size.)
It's a good example of how hard estimating is psychologically. Even though these numbers are quite clear, I still think "that can't be right". It seems like I'm making good progress. Yeah, there's lots left to do, but 8 months seems like such a long time. Then again, it's already been a month and a half and it feels like I just started yesterday.
This is when I start to rationalize/justify the lower (quicker) estimate that I want to hear. After all, at the start I was learning a new language and new IDE. And I had a lot of questions to figure out in terms of how I was going to handle the conversion. Once I get up to speed it should go faster, right? Well, maybe, but then again, things can slow down too, when you hit a snag or when you've got a million finishing touches to do.
Part of the problem is that it's much easier to maintain motivation and drive for a short period. Once a project extends as long as a year it's a lot tougher to keep up the momentum, and a lot easier to get distracted (like with replication!). However, the nagging issues with the current Suneido and the business drive towards larger clients will continue to provide motivation!
Friday, June 27, 2008
Lightweight Database Replication for Suneido
Issues
Occasionally we get runaway memory usage in Suneido. This only seems to happen with lots of users, and seems to be related to running large reports. I'm assuming it's due to the inherent problems with conservative garbage collection. Unfortunately, the fix is to restart the Suneido server program, but this is ugly, especially with a lot of active users.
Suneido is single-threaded so we don't take advantage of multiple cores.
Suneido does not have an ODBC interface. One of the reasons for this is that ODBC is quite closely tied to SQL and Suneido isn't SQL. A common reason for wanting this is to use third party report generation or data analysis tools. Or sometimes to interface with other systems.
We generally set up our clients to do on-line backups twice a day. Although this does not stop them from working, it does tend to slow down the system, especially with bigger databases. But it would be nice to do backups more often, since, in the event of a hardware failure, no one wants to lose even a few hours work. (And if the hard drive fails totally, they usually have to fall back on the nightly backup we do to Amazon S3.)
It would be nice in some circumstances to run Suneido on Amazon EC2. But EC2 doesn't have persistent storage (although they're working on it). You can load your database from S3 when you start the server and save it back to S3 when you stop the server. But if you crash, you lose it.
Replication
At RailsConf several of the sessions talked about using MySQL master-slave replication, for example to run on EC2. This got me thinking about replication for Suneido. Replication would, at least partially, address all the issues above.
- it would maintain an up to date backup with (hopefully) minimal impact on performance
- we could replicate to an SQL database, allowing ODBC access etc.
- we could run reports off the replica/slave, making use of multi-core, and reducing the memory issue because you could more easily restart the slave
- we could run on EC2 with the replica/slave to protect the data in case of crashes
Initially, I thought we could get some of these benefits just running a secondary server using the backups we already make twice a day. A lot of big reports don't need up to the minute data. But the problem would be determining when to use the live database and when to use the slightly stale copy. You could let the user pick but that would be ugly. And even they might not know that someone had just updated old data.
You could actually do replication at the application level by creating triggers for every database table and sending the changes to the slave. But it would be error prone and hard to handle issues like transaction rollbacks. It would also be running in the main thread so it could have a performance impact.
My next thought was to take advantage of the way Suneido's database is implemented - when a transaction is committed successfully a "commit" record is added to the end of the database file. So you can simply monitor the data added to the end of the file and watch for new commits.
One concern, that I haven't completely addressed, is whether different "views" of the file will be "coherent". MSDN is a little unclear on this. MapViewOfFile says:
I thought I might be able to use named file mapping objects to make sharing easier but I couldn't get it to work. I'm not sure what I was doing wrong, I didn't sink a lot of time into it.
Initially I thought I'd just create a separate thread within the server process to send the updates to the replica. Simpler than running a separate process and perhaps more likely to be coherent. As long as the replication thread did not access any of the server's variables, then there shouldn't be any concurrency issues. I went a little ways down this road until I realized that my memory management was single threaded. I could try to avoid any allocation in the replication thread but it's too hard to know what might allocate, making this approach error-prone and brittle.
So my current thinking is to make the replication a separate process. For simplicity, I will probably just make this another "mode" of running the same suneido.exe (Rather than creating a separate executable.) Suneido already works this way for standalone, client, or server - they're just different modes of running the same exe. (The exe is only just over 1 mb so it's not like having multiple modes is bloating it!)
Of course, I still have to handle the coherency issue.
What about the slave/replica? I should be able to run a standard Suneido server. The replication process can connect to it as a normal client (over TCP/IP sockets as usual). The basic functioning shouldn't require any changes. I may want to add a slave mode to tweak it to give the replication connection priority and to not allow updates from other connections.
The other piece of the puzzle is allowing a Suneido client to access multiple databases. Currently a client can only be connected to a single server. This will require some changes but they should be fairly minimal.
Replicating to an SQL database will be a little more work and it's less of a priority. (Until we get a client that demands it!)
I may be overly optimistic, but I think I can set this up with minimal effort. We'll see!
Occasionally we get runaway memory usage in Suneido. This only seems to happen with lots of users, and seems to be related to running large reports. I'm assuming it's due to the inherent problems with conservative garbage collection. Unfortunately, the fix is to restart the Suneido server program, but this is ugly, especially with a lot of active users.
Suneido is single-threaded so we don't take advantage of multiple cores.
Suneido does not have an ODBC interface. One of the reasons for this is that ODBC is quite closely tied to SQL and Suneido isn't SQL. A common reason for wanting this is to use third party report generation or data analysis tools. Or sometimes to interface with other systems.
We generally set up our clients to do on-line backups twice a day. Although this does not stop them from working, it does tend to slow down the system, especially with bigger databases. But it would be nice to do backups more often, since, in the event of a hardware failure, no one wants to lose even a few hours work. (And if the hard drive fails totally, they usually have to fall back on the nightly backup we do to Amazon S3.)
It would be nice in some circumstances to run Suneido on Amazon EC2. But EC2 doesn't have persistent storage (although they're working on it). You can load your database from S3 when you start the server and save it back to S3 when you stop the server. But if you crash, you lose it.
Replication
At RailsConf several of the sessions talked about using MySQL master-slave replication, for example to run on EC2. This got me thinking about replication for Suneido. Replication would, at least partially, address all the issues above.
- it would maintain an up to date backup with (hopefully) minimal impact on performance
- we could replicate to an SQL database, allowing ODBC access etc.
- we could run reports off the replica/slave, making use of multi-core, and reducing the memory issue because you could more easily restart the slave
- we could run on EC2 with the replica/slave to protect the data in case of crashes
Initially, I thought we could get some of these benefits just running a secondary server using the backups we already make twice a day. A lot of big reports don't need up to the minute data. But the problem would be determining when to use the live database and when to use the slightly stale copy. You could let the user pick but that would be ugly. And even they might not know that someone had just updated old data.
You could actually do replication at the application level by creating triggers for every database table and sending the changes to the slave. But it would be error prone and hard to handle issues like transaction rollbacks. It would also be running in the main thread so it could have a performance impact.
My next thought was to take advantage of the way Suneido's database is implemented - when a transaction is committed successfully a "commit" record is added to the end of the database file. So you can simply monitor the data added to the end of the file and watch for new commits.
One concern, that I haven't completely addressed, is whether different "views" of the file will be "coherent". MSDN is a little unclear on this. MapViewOfFile says:
Multiple views of a file ... are coherent ... if the file views are derived from the same file mapping object.But CreateFileMapping says:
file views derived from any file mapping object that is backed by the same file are coherentIf I had a single file mapping object it might not be too hard to share it with the replication task. But because I map large files in chunks, I have a whole bunch of file mapping objects which makes it harder to share them.
I thought I might be able to use named file mapping objects to make sharing easier but I couldn't get it to work. I'm not sure what I was doing wrong, I didn't sink a lot of time into it.
Initially I thought I'd just create a separate thread within the server process to send the updates to the replica. Simpler than running a separate process and perhaps more likely to be coherent. As long as the replication thread did not access any of the server's variables, then there shouldn't be any concurrency issues. I went a little ways down this road until I realized that my memory management was single threaded. I could try to avoid any allocation in the replication thread but it's too hard to know what might allocate, making this approach error-prone and brittle.
So my current thinking is to make the replication a separate process. For simplicity, I will probably just make this another "mode" of running the same suneido.exe (Rather than creating a separate executable.) Suneido already works this way for standalone, client, or server - they're just different modes of running the same exe. (The exe is only just over 1 mb so it's not like having multiple modes is bloating it!)
Of course, I still have to handle the coherency issue.
What about the slave/replica? I should be able to run a standard Suneido server. The replication process can connect to it as a normal client (over TCP/IP sockets as usual). The basic functioning shouldn't require any changes. I may want to add a slave mode to tweak it to give the replication connection priority and to not allow updates from other connections.
The other piece of the puzzle is allowing a Suneido client to access multiple databases. Currently a client can only be connected to a single server. This will require some changes but they should be fairly minimal.
Replicating to an SQL database will be a little more work and it's less of a priority. (Until we get a client that demands it!)
I may be overly optimistic, but I think I can set this up with minimal effort. We'll see!
Labels:
suneido
Thursday, June 26, 2008
Eclipse Ganymede
The latest version of Eclipse - Ganymede (3.4) is out. I couldn't figure out how to update/upgrade from within my existing installation. Maybe that's not possible between versions. So I just downloaded and installed the new version. The only problem with that was that I had to reinstall my plugins. But I could export/import my list of update sites which made it pretty easy.
Ganymede is a coordinated release of 23 projects representing over 18 million lines of code. I'm not sure I can really wrap my head around that. It makes my porting of a measly 60,000 lines of code sound like a drop in the bucket.
Check out the release notes - some cool new stuff. It's nice to see they've improved the plugin/update installation process.
I've been using TextMate to view the Suneido C++ code as I work on the Java version. It has a lot of devoted fans and some great features, but I've been having a hard time getting used to it. For example, the Find doesn't have a "whole words" option. I guess I could do it with regular expressions, but that seems awkward. It seems like every editor has that. And the normal Find also doesn't default to the selected text. Just little things, but they slow me down.
I've been getting more comfortable with Eclipse and getting spoilt by its features. I saw there was a new release of CDT (C & C++ Development Tools) with the new Eclipse so I thought I'd try it out. I still had to struggle to import the source into an Eclipse project. There is help for this but, as is so often the case, it isn't very helpful. I ended up importing from Subversion, which is probably good since I'll be able to check in any changes I make as I'm browsing the source. I didn't bother trying to set up a build environment since it won't build on the Mac anyway. But at least I can use the same tools to access both the Java and the C++ code.
Ganymede is a coordinated release of 23 projects representing over 18 million lines of code. I'm not sure I can really wrap my head around that. It makes my porting of a measly 60,000 lines of code sound like a drop in the bucket.
Check out the release notes - some cool new stuff. It's nice to see they've improved the plugin/update installation process.
I've been using TextMate to view the Suneido C++ code as I work on the Java version. It has a lot of devoted fans and some great features, but I've been having a hard time getting used to it. For example, the Find doesn't have a "whole words" option. I guess I could do it with regular expressions, but that seems awkward. It seems like every editor has that. And the normal Find also doesn't default to the selected text. Just little things, but they slow me down.
I've been getting more comfortable with Eclipse and getting spoilt by its features. I saw there was a new release of CDT (C & C++ Development Tools) with the new Eclipse so I thought I'd try it out. I still had to struggle to import the source into an Eclipse project. There is help for this but, as is so often the case, it isn't very helpful. I ended up importing from Subversion, which is probably good since I'll be able to check in any changes I make as I'm browsing the source. I didn't bother trying to set up a build environment since it won't build on the Mac anyway. But at least I can use the same tools to access both the Java and the C++ code.
Subscribe to:
Posts (Atom)